Объем выборки пример. Интервальное оценивание генеральной доли
Статистика знает все. И Ильф и Е. Петров, «12 Стульев»
Представьте себе, что вы строите крупный торговый центр и желаете оценить автомобильный поток въезда на территорию парковки. Нет, давайте другой пример… они все равно этого никогда не будут делать. Вам необходимо оценить вкусовые предпочтения посетителей вашего портала, для чего необходимо провести среди них опрос. Как увязать количество данных и возможную погрешность? Ничего сложного - чем больше ваша выборка, тем меньше погрешность. Однако и здесь есть нюансы.
Теоретический минимум
Не будет лишним освежить память, эти термины нам пригодятся далее.
- Популяция – Множество всех объектов, среди которых проводится исследования.
- Выборка – Подмножество, часть объектов из всей популяции, которая непосредственно участвует в исследовании.
- Ошибка первого рода - (α) Вероятность отвергнуть нулевую гипотезу, в то время как она верна.
- Ошибка второго рода - (β) Вероятность не отвергнуть нулевую гипотезу, в то время как она ложна.
- 1 - β - Статистическая мощность критерия.
- μ 0 и μ 1 - Средние значения при нулевой и альтернативной гипотезе.

Уже в самих определениях ошибки первого и второго рода имеется простор для дебатов и толкований. Как с ними определиться и какую выбрать в качестве нулевой? Если вы исследуете уровень загрязнения почвы или вод, то как сформулируете нулевую гипотезу: загрязнение присутствует, или нет загрязнения? А ведь от этого зависит объем выборки из общей популяции объектов.

Исходная популяция , также как и выборка может иметь любое распределение, однако среднее значение имеет нормальное или гауссово распределение благодаря Центральной Предельной Теореме .
Относительно параметров распределения и среднего значения в частности возможно несколько типов умозаключений. Первое из них называется доверительным интервалом . Он указывает на интервал возможных значений параметра, с указанным коэффициентом доверия . Так например 100(1-α)% доверительный интервал для μ будет таким (Ур. 1).
Второе из умозаключений - проверка гипотезы . Оно может быть примерно таким.
- H 0: μ = h
- H 1: μ > h
- H 2: μ < h
С доверительным интервалом 100(1-α) для μ можно сделать выбор в пользу H 1 и H 2:
- Если нижний предел доверительного интервала 100(1-α) < h , то тогда отвергаем H 0 в пользу H 2 .
- Если верхний предел доверительного интервала 100(1-α) > h, то тогда отвергаем H 0 в пользу H 1 .
- Если доверительного интервала 100(1-α) включает в себя h, то тогда мы не может отвергнуть H 0 и такой результат считается неопределенным .
Если нам нужно проверить значение μ для одной выборки из общей совокупности, то критерий обретет вид.
Доверительный интервал, погрешность и размер выборки
Возьмем самое первое уравнение и выразим оттуда ширину доверительного интервала (Ур. 2).
В некоторых случаях мы можем заменить t-статистику Стьюдента на z стандартного нормального распределения. Еще одним упрощением заменим половину от w на погрешность измерения E. Тогда наше уравнения примет вид (Ур. 3).
Как видим погрешность действительно уменьшается вместе с ростом количества входных данных . Откуда легко вывести искомое (Ур. 4).
Практика - считаем с R
Проверим гипотезу о том, что среднее значение данной выборки количества насекомых в ловушке равно 1.
- H 0: μ = 1
- H 1: μ > 1
| Насекомые | 0 | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|---|
| Ловушки | 10 | 9 | 5 | 5 | 1 | 2 | 1 |
> x <- read.table("/tmp/tcounts.txt") > y = unlist(x, use.names="false") > mean(z);sd(z) 1.636364 1.654883
Обратите внимание, что среднее и стандартное отклонение практически равны, что естественно для распределения Пуассона. Доверительный интервал 95% для t-статистики Стьюдента и df=32 .
> qt(.975, 32) 2.036933
и наконец получаем критический интервал для среднего значения: 1.05 - 2.22 .
> μ=mean(z) > st = qt(.975, 32) > μ + st * sd(z)/sqrt(33) 2.223159 > μ - st * sd(z)/sqrt(33) 1.049568
В итоге, следует отбраковать H 0 и принять H 1 так как с вероятностью 95%, μ > 1.
В том же самом примере, если принять, что нам известно действительное стандартное отклонение - σ , а не ее оценка полученная с помощью случайной выборки, можно рассчитать необходимое n для данной погрешности. Посчитаем для E=0.5 .
> za2 = qnorm(.975) > (za2*sd(z)/.5)^2 42.08144
Поправка на ветер
На самом деле нет никаких причин, полагать, что нам будет известна σ (дисперсия), в то время как μ (среднее) нам еще только предстоит оценить. Из-за этого уравнение 4 имеет мало практической пользы, кроме особо рафинированных примеров из области комбинаторики, а реалистичное уравнение для n несколько сложнее при неизвестной σ (Ур. 5).
Обратите внимание, что σ в последнем уравнении не с шапкой (^), а тильдой (~). Это следствие того, что в самом начале у нас нет даже оценочного стандартного отклонения случайной выборки - , и вместо нее мы используем запланированное - . Откуда же мы берем последнее? Можно сказать, что с потолка: экспертная оценка, грубые прикидки, прошлый опыт и т. д.
А что на счет второго слагаемого правой стороны 5-го уравнения, откуда оно взялось? Так как , необходима поправка Гюнтера .
Помимо уравнений 4 и 5 есть еще несколько приблизительно-оценочных формул, но это уже заслуживает отдельного поста.
Статистическая совокупность - множество единиц, обладающих массовостью, типичностью, качественной однородностью и наличием вариации.
Статистическая совокупность состоит из материально существующих объектов (Работники, предприятия, страны, регионы), является объектом .
Единица совокупности — каждая конкретная единица статистической совокупности.
Одна и таже статистическая совокупность может быть однородна по одному признаку и неоднородна по другому.
Качественная однородность — сходство всех единиц совокупности по какому-либо признаку и несходство по всем остальным.
В статистической совокупности отличия одной единицы совокупности от другой чаще имеют количественную природу. Количественные изменения значений признака разных единиц совокупности называются вариацией.
Вариация признака — количественное изменение признака (для количественного признака) при переходе от одной единицы совокупности к другой.
Признак - это свойство, характерная черта или иная особенность единиц, объектов и явлений, которая может быть наблюдаема или измерена. Признаки делятся на количественные и качественные. Многообразие и изменчивость величины признака у отдельных единиц совокупности называется вариацией .
Атрибутивные (качественные) признаки не поддаются числовому выражению (состав населения по полу). Количественные признаки имеют числовое выражение (состав населения по возрасту).
Показатель — это обобщающая количественно качестванная характеристика какого-либо свойства единиц или совокупности в цельм в конкретных условиях времени и места.
Система показателей — это совокупность показателей всесторонне отражающих изучаемое явление.
Например, изучается зарплата:- Признак — оплата труда
- Статистическая совокупность — все работники
- Единица совокупности — каждый работник
- Качественная однородность — начисленная зарплата
- Вариация признака — ряд цифр
Генеральная совокупность и выборка из нее
Основу составляет множество данных, полученных в результате измерения одного или нескольких признаков. Реально наблюдаемая совокупность объектов, статистически представленная рядом наблюдений случайной величины , является выборкой , а гипотетически существующая (домысливаемая) — генеральной совокупностью . Генеральная совокупность может быть конечной (число наблюдений N = const ) или бесконечной (N = ∞ ), а выборка из генеральной совокупности — это всегда результат ограниченного ряда наблюдений. Число наблюдений , образующих выборку, называется объемом выборки . Если объем выборки достаточно велик (n → ∞ ) выборка считается большой , в противном случае она называется выборкой ограниченного объема . Выборка считается малой , если при измерении одномерной случайной величины объем выборки не превышает 30 (n <= 30 ), а при измерении одновременно нескольких (k ) признаков в многомерном пространстве отношение n к k не превышает 10 (n/k < 10) . Выборка образует вариационный ряд , если ее члены являются порядковыми статистиками , т. е. выборочные значения случайной величины Х упорядочены по возрастанию (ранжированы), значения же признака называются вариантами .
Пример . Практически одна и та же случайно отобранная совокупность объектов — коммерческих банков одного административного округа Москвы, может рассматриваться как выборка из генеральной совокупности всех коммерческих банков этого округа, и как выборка из генеральной совокупности всех коммерческих банков Москвы, а также как выборка из коммерческих банков страны и т.д.
Основные способы организации выборки
Достоверность статистических выводов и содержательная интерпретация результатов зависит от репрезентативности выборки, т.е. полноты и адекватности представления свойств генеральной совокупности, по отношению к которой эту выборку можно считать представительной. Изучение статистических свойств совокупности можно организовать двумя способами: с помощью сплошного и несплошного . Сплошное наблюдение предусматривает обследование всех единиц изучаемой совокупности , а несплошное (выборочное) наблюдение — только его части.
Существуют пять основных способов организации выборочного наблюдения:
1. простой случайный отбор , при котором объектов случайно извлекаются из генеральной совокупности объектов (например с помощью таблицы или датчика случайных чисел), причем каждая из возможных выборок имеют равную вероятность. Такие выборки называются собственно-случайными ;
2. простой отбор с помощью регулярной процедуры осуществляется с помощью механической составляющей (например, даты, дня недели, номера квартиры, буквы алфавита и др.) и полученные таким способом выборки называются механическими ;
3. стратифицированный отбор заключается в том, что генеральная совокупность объема подразделяется на подсовокупности или слои (страты) объема так что . Страты представляют собой однородные объекты с точки зрения статистических характеристик (например, население делится на страты по возрастным группам или социальной принадлежности; предприятия — по отраслям). В этом случае выборки называются стратифицированными (иначе, расслоенными, типическими, районированными );
4. методы серийного отбора используются для формирования серийных или гнездовых выборок . Они удобны в том случае, если необходимо обследовать сразу "блок" или серию объектов (например, партию товара, продукцию определенной серии или население при территориально-административном делении страны). Отбор серий можно осуществить собственно-случайным или механическим способом. При этом проводится сплошное обследование определенной партии товара, или целой территориальной единицы (жилого дома или квартала);
5. комбинированный (ступенчатый) отбор может сочетать в себе сразу несколько способов отбора (например, стратифицированный и случайный или случайный и механический); такая выборка называется комбинированной .
Виды отбора
По виду различаются индивидуальный, групповой и комбинированный отбор. При индивидуальном отборе в выборочную совокупность отбираются отдельные единицы генеральной совокупности, при групповом отборе — качественно однородные группы (серии) единиц, а комбинированный отбор предполагает сочетание первого и второго видов.
По методу отбора различают повторную и бесповторную выборку.
Бесповторным называется отбор, при котором попавшая в выборку единица не возвращается в исходную совокупность и в дальнейшем выборе не участвует; при этом численность единиц генеральной совокупности N сокращается в процессе отбора. При повторном отборе попавшая в выборку единица после регистрации возвращается в генеральную совокупность и таким образом сохраняет равную возможность наряду с другими единицами быть использованной в дальнейшей процедуре отбора; при этом численность единиц генеральной совокупности N остается неизменной (метод в социально-экономических исследованиях применяется редко). Однако, при большом N (N → ∞) формулы для бесповторного отбора приближаются к аналогичным для повторного отбора и практически чаще используются последние (N = const ).
Основные характеристики параметров генеральной и выборочной совокупности
В основе статистических выводов проведенного исследования лежит распределение случайной величины , наблюдаемые же значения (х 1 , х 2 , … , х n) называются реализациями случайной величины Х (n — объем выборки). Распределение случайной величины в генеральной совокупности носит теоретический, идеальный характер, а ее выборочный аналог является эмпирическим распределением. Некоторые теоретические распределения заданы аналитически, т.е. их параметры определяют значение функции распределения в каждой точке пространства возможных значений случайной величины . Для выборки же функцию распределения определить трудно, а иногда невозможно, поэтому параметры оценивают по эмпирическим данным, а затем их подставляют в аналитическое выражение, описывающее теоретическое распределение. При этом предположение (или гипотеза ) о виде распределения может быть как статистически верным, так и ошибочным. Но в любом случае восстановленное по выборке эмпирическое распределение лишь грубо характеризует истинное. Важнейшими параметрами распределений являются математическое ожидание и дисперсия .
По своей природе распределения бывают непрерывными и дискретными . Наиболее известным непрерывным распределением является нормальное . Выборочными аналогами параметров идля него являются: среднее значение и эмпирическая дисперсия . Среди дискретных в социально-экономических исследованиях наиболее часто применяется альтернативное (дихотомическое) распределение. Параметр математического ожидания этого распределения выражает относительную величину (или долю ) единиц совокупности, которые обладают изучаемым признаком (она обозначена буквой ); доля совокупности, не обладающая этим признаком, обозначается буквой q (q = 1 — p) . Дисперсия же альтернативного распределения также имеет эмпирический аналог .
В зависимости от вида распределения и от способа отбора единиц совокупности по-разному вычисляются характеристики параметров распределения. Основные из них для теоретического и эмпирического распределений приведены в табл. 9.1.
Долей выборки k n называется отношение числа единиц выборочной совокупности к числу единиц генеральной совокупности:
k n = n/N .
Выборочная доля w — это отношение единиц, обладающих изучаемым признаком x к объему выборки n :
w = n n /n .
Пример. В партии товара, содержащей 1000 ед., при 5% выборке доля выборки k n в абсолютной величине составляет 50 ед. (n = N*0,05); если же в этой выборке обнаружено 2 бракованных изделия, то выборочная доля брака w составит 0,04 (w = 2/50 = 0,04 или 4%).
Так как выборочная совокупность отлична от генеральной, то возникают ошибки выборки .
Таблица 9.1 Основные параметры генеральной и выборочной совокупностей
Ошибки выборки
При любом (сплошном и выборочном) могут встретиться ошибки двух видов: регистрации и репрезентативности. Ошибки регистрации могут иметь случайный и систематический характер. Случайные ошибки складываются из множества различных неконтролируемых причин, носят непреднамеренный характер и обычно по совокупности уравновешивают друг друга (например, изменения показателей прибора при температурных колебаниях в помещении).
Систематические ошибки тенденциозны, так как нарушают правила отбора объектов в выборку (например, отклонения в измерениях при изменении настройки измерительного прибора).
Пример. Для оценки социального положения населения в городе предусмотрено обследовать 25% семей. Если при этом выбор каждой четвертой квартиры основан на ее номере, то существует опасность отобрать все квартиры только одного типа (например, однокомнатные), что обеспечит систематическую ошибку и исказит результаты; выбор же номера квартиры по жребию более предпочтителен, так как ошибка будет случайной.
Ошибки репрезентативности присущи только выборочному наблюдению, их невозможно избежать и они возникают в результате того, что выборочная совокупность не полностью воспроизводит генеральную. Значения показателей, получаемых по выборке, отличаются от показателей этих же величин в генеральной совокупности (или получаемых при сплошном наблюдении).
Ошибка выборочного наблюдения есть разность между значением параметра в генеральной совокупности и ее выборочным значением. Для среднего значения количественного признака она равна: , а для доли (альтернативного признака) — .
Ошибки выборки свойственны только выборочным наблюдениям. Чем больше эти ошибки, тем больше эмпирическое распределение отличается от теоретического. Параметры эмпирического распределения и являются случайными величинами, следовательно, ошибки выборки также являются случайными величинами, могут принимать для разных выборок разные значения и поэтому принято вычислять среднюю ошибку .
Средняя ошибка выборки есть величина , выражающая среднее квадратическое отклонение выборочной средней от математического ожидания. Эта величина при соблюдении принципа случайного отбора зависит прежде всего от объема выборки и от степени варьирования признака: чем больше и чем меньше вариация признака (следовательно, и значение ), тем меньше величина средней ошибки выборки . Соотношение между дисперсиями генеральной и выборочной совокупностей выражается формулой:
т.е. при достаточно больших можно считать, что . Средняя ошибка выборки показывает возможные отклонения параметра выборочной совокупности от параметра генеральной. В табл. 9.2 приведены выражения для вычисления средней ошибки выборки при разных методах организации наблюдения.
Таблица 9.2 Средняя ошибка (m) выборочных средней и доли для разных видов выборки
Где - средняя из внутригрупповых выборочных дисперсий для непрерывного признака;
Средняя из внутригрупповых дисперсий доли;
— число отобранных серий, — общее число серий;
 ,
,
где — средняя -й серии;
— общая средняя по всей выборочной совокупности для непрерывного признака;
 ,
,
где — доля признака в -й серии;
— общая доля признака по всей выборочной совокупности.
Однако о величине средней ошибки можно судить лишь с определенной, вероятностью Р (Р ≤ 1). Ляпунов А.М. доказал, что распределение выборочных средних , a следовательно, и их отклонений от генеральной средней, при достаточно большом числе приближенно подчиняется нормальному закону распределения при условии, что генеральная совокупность обладает конечной средней и ограниченной дисперсией.
Математически это утверждение для средней выражается в виде:

а для доли выражение (1) примет вид:
где  -
есть предельная ошибка выборки
, которая кратна величине средней ошибки выборки ,
а коэффициент кратности — есть критерий Стьюдента ("коэффициент доверия"), предложенный У.С. Госсетом (псевдоним "Student"); значения для разного объема выборки хранятся в специальной таблице.
-
есть предельная ошибка выборки
, которая кратна величине средней ошибки выборки ,
а коэффициент кратности — есть критерий Стьюдента ("коэффициент доверия"), предложенный У.С. Госсетом (псевдоним "Student"); значения для разного объема выборки хранятся в специальной таблице.

Следовательно, выражение (3) может быть прочитано так: с вероятностью Р = 0,683 (68,3%) можно утверждать, что разность между выборочной и генеральной средней не превысит одной величины средней ошибки m (t = 1) , с вероятностью Р = 0,954 (95,4%) — что она не превысит величины двух средних ошибок m (t = 2) , с вероятностью Р = 0,997 (99,7%) — не превысит трех значений m (t = 3) . Таким образом, вероятность того, что эта разность превысит трехкратную величину средней ошибки определяет уровень ошибки и составляет не более 0,3% .
В табл. 9.3 приведены формулы для вычисления предельной ошибки выборки.
Таблица 9.3 Предельная ошибка (D) выборки для средней и доли (р) для разных видов выборочного наблюдения
Распространение выборочных результатов на генеральную совокупность
Конечной целью выборочного наблюдения является характеристика генеральной совокупности. При малых объемах выборки эмпирические оценки параметров ( и ) могут существенно отклоняться от их истинных значений ( и ). Поэтому возникает необходимость установить границы, в пределах которых для выборочных значений параметров ( и ) лежат истинные значения ( и ).
Доверительным интервалом какого-либо параметра θгенеральной совокупности называется случайная область значений этого параметра, которая с вероятностью близкой к 1 (надежностью ) содержит истинное значение этого параметра.
Предельная ошибка выборки Δ позволяет определить предельные значения характеристик генеральной совокупности и их доверительные интервалы , которые равны:
Нижняя граница доверительного интервала получена путем вычитания предельной ошибки из выборочного среднего (доли), а верхняя — путем ее добавления.
Доверительный интервал для средней использует предельную ошибку выборки и для заданного уровня достоверности определяется по формуле:
Это означает, что с заданной вероятностью Р
, которая называется доверительным уровнем и однозначно определяется значением t
, можно утверждать, что истинное значение средней лежит в пределах от ![]() ,а истинное значение доли — в пределах от
,а истинное значение доли — в пределах от
При расчете доверительного интервала для трех стандартных доверительных уровней Р = 95%, Р = 99% и Р = 99,9% значение выбирается по . Приложения в зависимости от числа степеней свободы . Если объем выборки достаточно велик, то соответствующие этим вероятностям значения t равны: 1,96, 2,58 и 3,29 . Таким образом, предельная ошибка выборки позволяет определить предельные значения характеристик генеральной совокупности и их доверительные интервалы:
Распространение результатов выборочного наблюдения на генеральную совокупность в социально-экономических исследованиях имеет свои особенности, так как требует полноты представительности всех ее типов и групп. Основой для возможности такого распространения является расчет относительной ошибки :

где Δ % - относительная предельная ошибка выборки; , .
Существуют два основных метода распространения выборочного наблюдения на генеральную совокупность: прямой пересчет и способ коэффициентов .
Сущность прямого пересчета заключается в умножении выборочного среднего значения!!\overline{x} на объем генеральной совокупности .
Пример . Пусть среднее число детей ясельного возраста в городе оценено выборочным методом и составило человека. Если в городе 1000 молодых семей, то число необходимых мест в муниципальных детских яслях получают умножением этой средней на численность генеральной совокупности N = 1000, т.е. составит 1200 мест.
Способ коэффициентов целесообразно использовать в случае, когда выборочное наблюдение проводится с целью уточнения данных сплошного наблюдения.
При этом используют формулу:
где все переменные — это численность совокупности:
Необходимый объем выборки
Таблица 9.4 Необходимый объем (n) выборки для разных видов организации выборочного наблюдения
При планировании выборочного наблюдения с заранее заданным значением допустимой ошибки выборки необходимо правильно оценить требуемый объем выборки . Этот объем может быть определен на основе допустимой ошибки при выборочном наблюдении исходя из заданной вероятности , гарантирующей допустимую величину уровня ошибки (с учетом способа организации наблюдения). Формулы для определения необходимой численности выборки n легко получить непосредственно из формул предельной ошибки выборки. Так, из выражения для предельной ошибки:
непосредственно определяется объем выборки n :
Эта формула показывает, что с уменьшением предельной ошибки выборки Δ существенно увеличивается требуемый объем выборки , который пропорционален дисперсии и квадрату критерия Стьюдента .
Для конкретного способа организации наблюдения требуемый объем выборки вычисляется согласно формулам, приведенным в табл. 9.4.
Практические примеры расчета
Пример 1. Вычисление среднего значения и доверительного интервала для непрерывного количественного признака.
Для оценки скорости расчета с кредиторами в банке проведена случайная выборка 10 платежных документов. Их значения оказались равными (в днях): 10; 3; 15; 15; 22; 7; 8; 1; 19; 20.
Необходимо с вероятностью Р = 0,954 определить предельную ошибку Δ выборочной средней и доверительные пределы среднего времени расчетов.
Решение. Среднее значение вычисляется по формуле из табл. 9.1 для выборочной совокупности
![]()
Дисперсия вычисляется по формуле из табл. 9.1.
![]()
Средняя квадратическая погрешность дня.
Ошибка средней вычисляется по формуле:
![]()
т.е. среднее значение равно x ± m = 12,0 ± 2,3 дней .
Достоверность среднего составила
![]()
Предельную ошибку вычислим по формуле из табл. 9.3 для повторного отбора, так как численность генеральной совокупности неизвестна, и для Р = 0,954 уровня достоверности.
Таким образом, среднее значение равно `x ± D = `x ± 2m = 12,0 ± 4,6, т.е. его истинное значение лежит в пределах от 7,4 до16,6 дней.
Использование таблицы Стьюдента. Приложения позволяет заключить, что для n = 10 — 1 = 9 степеней свободы полученное значение достоверно с уровнем значимости a £ 0,001, т.е. полученное значение среднего достоверно отличается от 0.
Пример 2. Оценка вероятности (генеральной доли) р.
При механическом выборочном способе обследования социального положения 1000 семей выявлено, что доля малообеспеченных семей составила w = 0,3 (30%) (выборка была 2% , т.е. n/N = 0,02 ). Необходимо с уровнем достоверности р = 0,997 определить показатель р малообеспеченных семей во всем регионе.
Решение. По представленным значениям функции Ф(t) найдем для заданного уровня достоверности Р = 0,997 значение t = 3 (см. формулу 3). Предельную ошибку доли w определим по формуле из табл. 9.3 для бесповторного отбора (механическая выборка всегда является бесповторной):
Предельная относительная ошибка выборки в % составит:
Вероятность (генеральная доля) малообеспеченных семей в регионе составит р=w±Δ w , а доверительные пределы р вычисляются исходя из двойного неравенства:
w — Δ w ≤ p ≤ w — Δ w , т.е. истинное значение р лежит в пределах:
0,3 — 0,014 < p <0,3 + 0,014, а именно от 28,6% до 31,4%.
Таким образом, с вероятностью 0,997 можно утверждать, что доля малообеспеченных семей среди всех семей региона составляет от 28,6% до 31,4%.
Пример 3. Вычисление среднего значения и доверительного интервала для дискретного признака, заданного интервальным рядом.
В табл. 9.5. задано распределение заявок на изготовление заказов по срокам их выполнения предприятием.
Таблица 9.5 Распределение наблюдений по срокам появленияРешение. Средний срок выполнения заявок вычисляется по формуле:
Средний срок составит:
= (3*20 + 9*80 + 24*60 + 48*20 + 72*20)/200 = 23,1 мес.
Тот же ответ получим, если используем данные о р i из предпоследней колонки табл. 9.5, используя формулу:
Заметим, что середина интервала для последней градации находится путем искусственного ее дополнения шириной интервала предыдущей градации равной 60 — 36 = 24 мес.
Дисперсия вычисляется по формуле
![]()
где х i - середина интервального ряда.
Следовательно!!\sigma = \frac {20^2 + 14^2 + 1 + 25^2 + 49^2}{4}, а средняя квадратическая погрешность .
Ошибка средней вычисляется по формуле мес., т.е. среднее значение равно!!\overline{x} ± m = 23,1 ± 13,4.
Предельную ошибку вычислим по формуле из табл. 9.3 для повторного отбора, так как численность генеральной совокупности неизвестна, для 0,954 уровня достоверности:
Таким образом, среднее значение равно:
т.е. его истинное значение лежит в пределах от 0 до 50 мес.
Пример 4. Для определения скорости расчетов с кредиторами N = 500 предприятий корпорации в коммерческом банке необходимо провести выборочное исследование методом случайного бесповторного отбора. Определить необходимый объем выборки n, чтобы с вероятностью Р = 0,954 ошибка среднего значения выборки не превышала 3-х дней, если пробные оценки показали, что среднее квадратическое отклонение s составило 10 дней.
Решение . Для определения числа необходимых исследований n воспользуемся формулой для бесповторного отбора из табл. 9.4:

В ней значение t определяется из для уровня достоверности Р = 0,954. Оно равно 2. Среднее квадратическое значение s = 10, объем генеральной совокупности N = 500, а предельная ошибка среднего значения Δ x = 3. Подставляя эти значения в формулу, получим:
![]()
т.е. выборку достаточно составить из 41 предприятия, чтобы оценить требуемый параметр — скорость расчетов с кредиторами.
Населения нередко проводятся среди больших групп людей. Зачастую ошибочным является представление о том, что достоверность результатов будет выше, если на вопросы ответит каждый член общества. Вследствие огромных временных, денежных затрат и трудоемкости такое обследование оказывается неприемлемым. С ростом численности респондентов не только увеличатся расходы, но и возрастет риск получения неверных данных. С практической точки зрения множество анкетеров и кодировщиков снизят вероятность достоверного контроля их действий. Такой опрос называется сплошным.
В социологии чаще всего применяется несплошное исследование, или выборочный метод. Результаты его могут распространяться на большую совокупность людей, которая именуется генеральной.
Определение и значение выборочного метода
Выборочный метод- это количественный способ отбора части исследуемых единиц из общей массы, при этом итоги обследования будут распространяться и на каждого индивида, не принявшего участия в этом.
Выборочный метод является и предметом научного исследования, и учебной дисциплиной. Он выступает средством получения достоверной информации о генеральной совокупности и помогает дать оценку всех ее параметров. Условия отбора единиц влияют в последующем на статистический анализ результатов. Если выборочные процедуры осуществлены некачественно, использование даже самых надежных методов обработки собранной информации окажется бесполезным.

Ключевые понятия теории выбора
Называют взаимосвязь единиц, относительно которых формулируются выводы выборочного исследования. В качестве нее могут выступать жители одной страны, конкретного населенного пункта, рабочий коллектив предприятия и т. д.
Выборочную совокупность (или выборку) составляет часть генеральной, которая была выделена с использованием специальных методик и критериев. Например, в процессе формирования учитываются статистические критерии.
Количество индивидов, вошедших в ту или иную совокупность, называют ее объемом. Но он может быть выражен не только числом людей, но и избирательными участками, населенными пунктами, то есть определенно крупными единицами, включающими в себя единицы наблюдения. Но это уже является многоступенчатой выборкой.
Единицей отбора являются составные части генеральной совокупности, ими могут быть как непосредственно единицы наблюдения (одноступенчатая выборка), так и более крупные формирования.
Большую роль в получении достоверных результатов исследования с применением выборочного метода является такое свойство, как репрезентативность отбора. То есть часть генеральной совокупности, ставшая респондентами, должна полностью воспроизводить все ее характеристики. Любое отклонение признается ошибкой.

Этапы применения выборочного метода
Каждое эмпирическое состоит из этапов. В случае применения выборочного метода их очередность будет выстроена следующим образом:
- Создание проекта выборки: устанавливается генеральная совокупность, характеризуются процедуры выбора, объемы.
- Реализация проекта: в ходе сбора социологической информации происходит выполнение анкетерами заданий с указанием способом отбора респондентов.
- Выявление и корректировка ошибок репрезентативности.
Типы выборок в социологии
После определения генеральной совокупности исследователь переходит к выборочным процедурам. Они могут разделяться по двум видам (критериям):
- Роль вероятностных законов в ходе осуществления выборки.
- Количество ступеней отбора.
Если применять первый критерий, то выделяют метод случайной выборки и неслучайный отбор. На основании последнего можно утверждать, что выборка может быть одноступенчатой и многоступенчатой.
Типы выборокпрямым образом отражаются не только на этапах подготовки и проведения исследования, но и на его результатах. Прежде чем отдать предпочтение одному из них, следует разобраться в содержании понятий.
Определение «случайный» в бытовом применении получило совершенно противоположенное значение, чем в математике. Такой отбор осуществляется по строгим правилам, не допускается никакое отступление от них, так как важно обеспечить каждой единице генеральной совокупности одинаковые шансы быть включенной в выборку. При несоблюдении данных условий эта вероятность будет разной.
В свою очередь случайная выборка подразделяется на:
- простую;
- механическую (систематическую);
- гнездовую (серийную, кластерную);
- стратифицированную (типическую или районированную).
Простой выборочный метод осуществляется при помощи таблицыслучайных чисел. Первоначально определяется объем выборки; создается полный перечень пронумерованных респондентов, входящих в генеральную совокупность. Используются для отбора специальные таблицы, содержащиеся в математико-статистических изданиях. Любые отличные от них применять запрещается. Если объем выборкипредставляет трехзначное число, то номер каждой единицы отбора должен быть трехзначным, а именно: от 001 до 790. Последнее число означает общее количество человек. В исследовании примут участие те люди, которым был присвоен номер в указанном диапазоне, встречающийся в таблице.

Систематический отбор основан на вычислениях. Предварительно составляется алфавитный список всех элементов генеральной совокупности, устанавливается шаг и только потом - объем выборки. Формула для шагапредставлена следующим образом:
N: n, где N - генеральная совокупность, а n - выборка.
Например, 150 000: 5 000 = 30. Таким образом, каждый тридцатый человек будет отобран для участия в опросе.
Сущность гнездового типа
Гнездовая выборка используется в условиях, если исследуемая совокупность людей состоит из маленьких по числу естественных групп. В таком случае следует учесть, что на первом шаге определяется списочное количество таких гнезд. При помощи таблицы случайных чисел происходит отбор и проводится сплошной опрос всех респондентов, состоящих в каждом отобранном гнезде. При этом чем больше их приняло участие в исследовании, чем меньше средняя ошибка выборки. Однако использовать такую методику возможно при условии наличия схожего признака у изучаемых гнезд.
Сущность стратифицированного выбора
Стратифицированная выборка отличается от предыдущих тем, что накануне отбора генеральная совокупность разбивается на страты, то есть однородные части, имеющие общий признак. Например, уровень образования, электоральные предпочтения, уровень удовлетворенности различными сторонами жизни. Самым простым вариантом является разделение испытуемых по полу и возрасту. Принципиально необходимо провести отбор таким образом, чтобы из каждой страты было выделено число лиц, пропорциональное общему количеству.
Объем выборки в таком случае может быть меньшим, чем в ситуации со случайным отбором, но при этом репрезентативность будет выше. Следует признать, что стратифицированная выборка будет самой затратной в финансовом и информационном плане, а гнездовая - самой выгодной в этом плане.

Неслучайная квотная выборка
Существует также квотная выборка. Она - единственный вид неслучайного отбора, который имеет математическое обоснование. Квотная выборка формируется из единиц, которые должны быть представлены пропорциями и соответствовать генеральной совокупности. В таким виде осуществляется целенаправленное распределение признаков. Если в числе исследуемых признаков выступают мнения, оценки людей, то квотными являются зачастую пол, возраст, образование респондентов.
В социологическом исследовании выделяют также два способа отбора: повторный и бесповторный. При первом избранная единица после обследования возвращается в генеральную совокупность, чтобы дальше участвовать в отборе. Во втором варианте респонденты отсортировываются, что повышает шансы остальных членов генеральной совокупности быть выбранным.
Ученый-социолог Г. А. Черчилль разработал такое правило: размер выборки должен стремиться обеспечить не меньше 100 наблюдений для первостепенных и 20-50 для второстепенной классификационной составляющей. Следует иметь в виду, что часть респондентов, вошедших в выборку, по различным причинам может не принять участие в опросе или вовсе от него отказаться.

Способы определения объема выборки
В социологических исследованиях применимы такие методы:
1. Произвольный, то есть объем выборки определяется в пределах 5-10 % состава генеральной совокупности.
2. Традиционный метод расчета основывается на проведении регулярных исследований, например, один раз в год с охватом 600, 2 000 или 2 500 респондентов.
3. Статистический - заключается в установлении надежности информации. Статистика как наука не развивается изолированно. Предметы и области ее исследования активно задействуются в других смежных отраслях: технических, экономических и гуманитарных. Так, ее методы используются в социологии, при подготовке к опросам и, в частности, при определении объемов выборок. Статистика как наука обладает обширной методологической базой.
4. Затратный, при котором установлена допустимая сумма расходов на исследование.
5. Объем выборки равен может быть числу единиц генеральной совокупности, тогда исследование будет носить сплошной характер. Такой подход применим в малых группах. Например, трудовой коллектив, студенты и т. д.
Ранее удалось установить, что выборка будет считаться репрезентативной, когда ее характеристики описывают свойства генеральной совокупности с минимальной погрешностью.
Оценка объема выборки предваряет окончательные расчеты количества единиц, которые будут выделены из генеральной совокупности:
n = Npqt 2: N∆ 2 p + pqt 2 , в которой N - количество единиц генеральной совокупности, p - доля изучаемого признака (q = 1 - p), t - коэффициент соответствия доверительной вероятности Р (определяется по специальной таблице), ∆ p - допустимая ошибка.
Это только один вариант того, как вычисляется объем выборки. Формула может изменяться в зависимости от условий и выбранных критериев исследования (например, повторная или бесповторная выборка).
Ошибки выборки
Социологические опросы населения основываются на использовании одного из типов выборки, рассмотренных нами выше. Однако в любом случае задачей каждого исследователя должна стать оценка степени точности полученных показателей, то есть нужно определить, насколько они отражают характеристики генеральной совокупности.
Ошибки выборки можно разделить на случайные и неслучайные. Первый вид подразумевает отклонение выборочного показателя от генерального, которое можно выразить разностью их долей (средней) и которое вызвано только не сплошным типом обследования. И совершенно закономерно, если этот показатель снижается на фоне увеличения количества опрошенных респондентов.
Систематической ошибкой называют отклонение от генерального показателя, также найденное в результате вычитания выборочной и генеральной доли и возникшее из-за несоответствия методики формирования выборки установленным правилам.
Данные типы ошибок входят в общую ошибку выборки. В исследовании из генеральной совокупности можно извлечь только одну выборку. Расчет величины максимально возможного отклонения выборочного показателя можно выполнить по специальной формуле. Оно называется предельной ошибкой выборки. Существует также такое понятие, как средняя ошибка выборки. Это среднее квадратическое отклонение выборочных от генеральной долей.
Выделяют также апостериорный (послеопытный) вид ошибки. Под ним подразумевается отклонение показателей выборочной от генеральной доли (средней). Оно вычисляется методом сравнения генерального показателя, информация о котором поступила от надежных источников, и выборочного, который был установлен в ходе опроса. В качестве достоверных источников информации выступают нередко отделы кадров предприятий, государственные органы статистики.
Существует также априорная ошибка, также являющаяся отклонением выборочного и генерального показателей, которой можно выразить разностью их долей и рассчитать которую можно по специальной формуле.

В учебных исследованиях чаще всего совершаются следующие ошибки, связанные с проведением отбора респондентов для опроса:
1. Выборочные совокупности групп, принадлежащие к разным генеральным. При их использовании разрабатываются статистические выводы, которые относятся ко всей выборке. Совершенно очевидно, что это не может быть приемлемо.
2. В расчет не принимаются организационные и финансовые возможности исследователя, когда рассматриваются типы выборок, и одной из них отдается предпочтение.
3. Не в полном объеме используются статистические критерии структуры генеральной совокупности при предотвращении ошибок выборки.
4. Не учитываются требования репрезентативности отбора респондентов в ходе сравнительных исследований.
5. Инструкция для интервьюера должна быть адаптирована с учетом специфики принятого типа отбора.
Характер участия респондентов в исследовании может быть открытым или анонимным. Это следует учитывать про формировании выборки, так как, не согласившись с условиями, участники могут выбыть.
Точность -- степень ошибочности результатов обследования или размер доверительного интервала.
Абсолютная точность задается определенным интервалом, в котором должно находиться оцениваемое значение.
Относительная точность определяется относительно уровня оценки параметра.
Достоверность -- степень уверенности в том, что оценка близка к истинному значению.
При определении объема выборки следует принимать во внимание некоторые качественные факторы: важность принимаемого решения, характер исследования, количество переменных, характер анализа, объемы выборки, которые использовались в подобных исследованиях, коэффициент охвата, коэффициент завершенности, а также ограниченность ресурсов. Статистически определенный объем выборки -- это чистый, или конечный, объем выборки, т.е. единицы совокупности, остающиеся после исключения потенциальных респондентов, которые не отвечают заданным критериям или не закончили интервью. В зависимости от коэффициентов охвата и завершенности может потребоваться намного больший объем исходной выборки. В коммерческих маркетинговых исследованиях недостаток времени, денег и хороших специалистов может иметь решающее значение при определении объема выборки. В проекте исследования постоянных покупателей универсального магазина объем выборки определялся именно по этим соображениям.
Метод доверительных интервалов:
Определение объема выборки методом доверительных интервалов основано на их создании вокруг выборочного среднего или выборочной доли с использованием формулы стандартной ошибки. В качестве примера предположим, что исследователь с помощью простого случайного отбора сформировал выборку из 300 семей для того, чтобы оценить ежемесячные расходы семьи на покупки в универмаге, и определил, что средний ежемесячный расход семьи в выборке равен 182 долл. Предыдущие исследования показали, что среднеквадратичное отклонение расходов в исследуемой совокупности равно 55 долл.
Мы хотим найти интервал, в который попадал бы определенный процент выборочных средних. Предположим, мы хотим определить интервал вокруг среднего значения совокупности, который включал бы 95% выборочных средних, опираясь на выборку из 300 семей; 95% выборочных средних можно разделить на две равные части, половина меньше и половина больше среднего, как показано на рис. 1. Вычисление доверительного интервала включает определение области меньше (XL) и больше (ХU) среднего значения (X) величины расходов.
Значения коэффициента z, соответствующие XL и ХU, можно рассчитать следующим образом:
Следовательно, минимальное значение X определяется как
а максимальное значение
Теперь установим 95%-ный доверительный интервал вокруг выборочного среднего, равного 182 долл. Для начала мы вычислим стандартную ошибку среднего:
Центральные 95% нормального распределения находятся в пределах?1,96 значений коэффициента z; 95%-ный доверительный интервал определяется как
Таким образом, 95%-ный доверительный интервал простирается от 175,77 до 188,23 долл. Вероятность нахождения истинного среднего значения наблюдаемой совокупности в пределах от 175,77 до 188,23 долл. составляет 95%.
Метод среднего:
Метод, использованный для создания доверительного интервала, можно модифицировать так, чтобы определить объем выборки с учетом желательного доверительного интервала. Предположим, что вы хотите рассчитать ежемесячный расход семьи на покупки в универмаге более точно -- так, чтобы полученный результат находился в пределах 5,0 долл. от истинного среднего значения исследуемой совокупности. Каким должен быть объем выборки? В таблице приведен необходимый перечень действий, которые вы должны выполнить.

- 1. Определите степень точности. Это максимально допустимое различие (D) между выборочным средним и генеральным средним. В нашем примере D = +5,0 долл.
- 2. Укажите уровень достоверности. Предположим, желательный уровень достоверности 95%.
- 3. Определите значение нормированного отклонения z, связанное с данным уровнем достоверности. При 95%-ном уровне достоверности вероятность того, что среднее значение генеральной совокупности выйдет за пределы одностороннего интервала, равна 0,025 (0,05/2). Соответствующее значение z составляет 1,96.
- 4. Определите стандартное отклонение среднего генеральной совокупности. Его можно получить из вторичных источников или рассчитать, проведя пилотное исследование. Кроме того, стандартное отклонение можно установить на основе мнения исследователя. Например, диапазон нормально распределенной переменной примерно укладывается в шесть стандартных отклонений (по три слева и справа от среднего значения).
5. Определите объем выборки, воспользовавшись формулой стандартной ошибки среднего
В нашем примере

(округленное в большую сторону до ближайшего целого числа).
Из формулы объема выборки видно, что он растет с ростом изменчивости (дисперсии) генеральной совокупности, а также с увеличением уровня достоверности и степени точности, с которой должны проводиться расчеты. Объем выборки прямо пропорционален Q2, поэтому, чем больше показатель дисперсии генеральной совокупности, тем больше объем выборки. Аналогично, более высокий уровень достоверности предполагает большее значение z и, следовательно, больший объем выборки. Переменные Q2 и z находятся в числителе. Увеличение степени точности достигается уменьшением значения D и, следовательно, увеличивает объем выборки, поскольку D находится в знаменателе.
6. Если объем выборки составляет 10% и больше от объема генеральной совокупности, то применяется окончательная коррекция совокупности (fpc). Затем необходимый объем выборки рассчитывается по формуле
7. Если среднеквадратичное отклонение совокупности о неизвестно и используется его предположительное значение, то его следует повторно рассчитать после получения выборки. Среднеквадратичное отклонение выборки s используется в качестве предположительного значения Q. Затем следует вычислить исправленный доверительный интервал, чтобы определить фактически полученную степень точности.
Предположим, что значение 55,00 использовалось в качестве предположительного значения а, потому что истинное значение было неизвестно. Получена выборка, в которой n = 465. На основе данных исследования рассчитывается среднее X, равное 180,00, и среднеквадратичное отклонение выборки s, равное 50,00. Тогда исправленный доверительный интервал составит:
Обратите внимание, что полученный доверительный интервал уже предполагаемого. Это вызвано тем, что среднеквадратичное отклонение совокупности завышено на основании выборочных характеристик.
8. Иногда точность определена в относительных, а не в абсолютных показателях. Другими словами, может быть известно, что результат вычисления должен составить плюс-минус R% от среднего. В этом случае объем выборки можно определить как
Объем генеральной совокупности N не влияет на объем выборки напрямую, за исключением случаев, когда применяется коэффициент окончательной коррекции совокупности. Возможно, это кажется невероятным, но если подумать, в этом утверждении есть смысл. Например, если исследуемые характеристики всех элементов совокупности идентичны, то выборки, состоящей из одного элемента, вполне достаточно, чтобы рассчитать среднее. Это также правильно, если совокупность состоит из 50, 500, 5000 или 50 000 элементов. В то же время изменчивость характеристик совокупности напрямую влияет на объем выборки. Эта изменчивость учитывается при вычислении объема выборки с помощью генеральной дисперсии Q2 или выборочной дисперсии s2.
Метод доли:
Если изучаемая статистика представлена не средним, а долей, то маркетолог определяет объем выборки аналогичным образом. Предположим, что исследователя интересует установление доли семей, владеющих кредитной карточкой универмага. Порядок действий будет следующим.
1. Укажите степень точности. Предположим, желательная степень точности такова, что допустимый интервал установлен на уровне
D = р -- л = ±0,05.
- 2. Укажите уровень достоверности. Предположим, что желателен 95%-ный уровень достоверности.
- 3. Определите значение z, связанное с данным уровнем достоверности. Как объяснялось при расчете среднего, оно составит 1,96.
- 4. Определите генеральную долю п. Как мы указывали раньше, ее можно получить из вторичных источников, в ходе экспериментального исследования или на основе мнения исследователя. Предположим, что на основе вторичных данных исследователь делает предположение, что 64% семей из изучаемой генеральной совокупности обладают кредитной карточкой универмага. Следовательно, л = 0,64.
- 5. Определите объем выборки с помощью формулы стандартной ошибки доли:
В нашем примере
- (округленное в большую сторону до целого числа).
- 6. Если конечный объем выборки составляет 10% и больше от объема совокупности, применяется окончательная коррекция совокупности (fpc). Затем необходимый объем выборки рассчитывается по формуле
где n -- объем выборки до применения окончательной коррекции; nс -- объем выборки после применения окончательной коррекции.
7. Если расчет тс был неверным, то доверительный интервал будет более или менее точным по сравнению с необходимым. Предположим, что по окончании выборки рассчитывается значение доли p, равное 0,55. Затем повторно вычисляется доверительный интервал, при этом sp используется для расчета неизвестного Qp , а именно:
В нашем примере
Доверительный интервал тогда равен 0,55 ± 1,96 (0,0264) = 0,55 + 0,052, что означает, что он шире, чем было задано. Это объясняется тем, что среднеквадратичное отклонение выборки p = 0,55 оказалось большим, чем предположительное значение среднеквадратичного отклонения генеральной совокупности при л = 0,64.
Если интервал, превышающий указанный, недопустим, объем выборки можно скорректировать так, чтобы отразить максимально возможное отклонение в генеральной совокупности. Такое отклонение происходит, когда произведение л (1 -- л) достигает максимального значения, для чего л должно равняться 0,5. К этому выводу можно прийти и без расчетов. Поскольку у одной половины совокупности одно значение характеристики, а у другой -- другое, потребуется больше данных, чтобы сделать правильный вывод, нежели когда ситуация более четко определена и у большинства элементов одно значение характеристики. В нашем примере это приведет к получению объема выборки, равного
- (округлено в большую сторону до целого числа).
- 8. Иногда точность определена в относительных, а не в абсолютных показателях. Другими словами, может быть известно, что результат вычисления должен составить плюс-минус R% от доли совокупности. Это означает, что D =Rл. В этом случае объем выборки можно определить как
Процедура составления плана выборки включает последовательное решение трех следующих задач:
Определение объекта исследования;
Определение структуры выборки;
Определение объема выборки.
Как правило, объект маркетингового исследования представляет собой совокупность объектов наблюдения, в качестве которых могут выступать потребители, сотрудники компании, посредники и т.д. Если эта совокупность настолько малочисленна, что исследовательская группа располагает необходимыми трудовыми, финансовыми и временными возможностями для установления контакта с каждым из ее элементов, то вполне реально проведение сплошного исследования всей совокупности. В этом случае, определив объект исследования, можно приступать к следующей процедуре (выбору метода сбора данных, орудия исследования и способа связи с аудиторией).
Однако на практике очень часто не представляется возможным или целесообразным проведение сплошного исследования всей совокупности. Для этого могут быть следующие причины:
Невозможность установления контакта с некоторыми элементами совокупности;
Неоправданно большие расходы на проведение сплошного исследования или наличие финансовых ограничений, не позволяющих проведение сплошного исследования;
Сжатые сроки, отведенные для исследования, обусловленные утратой со временем актуальности информации или другими причинами и не позволяющие осуществить сбор, систематизацию и анализ обширных данных для всей совокупности.
Поэтому большие и разбросанные совокупности часто изучаются с помощью выборки, под которой, как известно, понимается часть совокупности, призванная олицетворять совокупность в целом.
Точность, с которой выборка отражает совокупность в целом, зависит от структуры и размера выборки .
Различают два подхода к структуре выборки - вероятностный и детерминированный.
Вероятностный подход к структуре выборки предполагает, что любой элемент совокупности может быть выбран с определенной (не нулевой) вероятностью. Существуют различные виды выборок, основанных на теории вероятностей (типическая, гнездовая и др.). Наиболее простой и распространенной на практике является простая случайная выборка, при которой каждый элемент совокупности имеет равную вероятность выбора для исследования.
Вероятностная выборка более точна, позволяет исследователю оценить степень достоверности собранных им данных, хотя она сложней и дороже, чем детерминированная.
Детерминированный подход к структуре выборки предполагает, что выбор элементов совокупности производится методами, основанными либо на соображениях удобства, либо на решении исследователя, либо на контингентных группах.
на соображениях удобства , состоит в выборе любых элементов совокупности исходя из простоты установления контакта с ними. Несовершенство этого метода обусловлено, возможно, низкой репрезентативностью полученной выборки, т.к. удобные для исследователя элементы совокупности могут быть недостаточно характерными представителями совокупности в силу неслучайного и необоснованного их отбора.
Однако, с другой стороны, простота, экономичность и оперативность исследования, проводимого этим методом, снискали ему довольно широкое распространение на практике и, прежде всего при проведении предварительных исследований, направленных на уточнение основных проблем.
Метод формирования выборки, основанный на решении исследователя , состоит в выборе элементов совокупности, которые, по его мнению, являются ее характерными представителями. Этот метод является более совершенным, чем предыдущий, поскольку в его основе лежит ориентировка на характерных представителей исследуемой совокупности, хотя и подбираемых на основе субъективных представлений исследователей о ней.
Метод формирования выборки, основанный на контингентных нормах , состоит в выборе характерных элементов совокупности в соответствии с полученными ранее характеристиками совокупности в целом. Эти характеристики могут быть получены путем проведения предварительных исследований и в отличие от предыдущего метода не носят субъективного характера. Поэтому данный метод является более совершенным, он позволяет получить выборочные совокупности не менее представительные, чем вероятностные выборки при значительно меньших затратах на проведение обследования.
Выбрав структуру выборки (подход к ее формированию, вид вероятностной или метая формирования детерминированной выборки), исследователю предстоит определить объем, т.е. количество элементов выборочной совокупности.
Объем выборки определяет достоверность информации , полученной в результате ее исследования, а также необходимые для проведения исследования затраты. Объем выборки зависит от уровня однородности или разновидности изучаемых объектов.
Чем больше объем выборки, тем выше ее точность и больше затраты на проведения ее обследования. При вероятностном подходе к структуре выборки ее объем может быть определен с помощью известных статистических формул, на основе заданных требований к ее точности.
На практике используется несколько подходов к определению объема выборки:
1. Произвольный подход основан на применении «правила большого пальца». Например, бездоказательно принимается, что для получения точных результатов выборка должна составлять 5 % от совокупности. Данный подход является простым и легким в исполнении, однако не представляется возможным установить точность полученных результатов. При достаточно большой совокупности он к тому же может быть и весьма дорогим.
Объем выборки может быть установлен исходя из неких заранее оговоренных условий. К примеру, заказчик маркетингового исследования знает, что при изучении общественного мнения выборка обычно составляет 1000-1200 человек, поэтому он рекомендует исследователю придерживаться данной цифры. В случае, если на каком-то рынке проводятся ежегодные исследования, то в каждом году используется выборка одного и того же объема. В отличие от первого подхода здесь при определении объема выборки используется известная логика, которая, однако, является весьма уязвимой.
Например, при проведении определенных исследований может потребоваться точность меньше, чем при изучении общественного мнения, да и объем совокупности может быть во много раз меньше, нежели при изучении общественного мнения. Таким образом, данный подход не принимает в расчет текущие обстоятельства и может быть достаточно дорогим.
В ряде случаев в качестве главного аргумента при определении объема выборки используется стоимость проведения обследования. Так, в бюджете маркетинговых исследований предусматриваются затраты на проведение определенных обследований, которые нельзя превышать. Очевидно, что ценность получаемой информации не принимается в расчет. Однако в ряде случаев и малая выборка может дать достаточно точные результаты.
Представляется разумным учитывать затраты не абсолютным образом, а по отношению к полезности информации, полученной в результате проведенных обследований. Заказчик и исследователь должны рассмотреть различные объемы выборки и методы сбора данных, затраты, учесть другие факторы
2. Объем выборки от уровня доверительного интервала допустимой ошибки, каковая, как уже говорилось, задается целесообразной точностью итоговых обобщений: от повышенной до ориентировочной. Однако здесь имеются в виду так называемые случайные ошибки, связанные с природой любых статистических погрешностей. Именно они и вычисляются как ошибки репрезентативности вероятностных выборок.
В. И. Паниотто приводит следующие расчеты репрезентативной выборки с допущением 5-процентной ошибки (табл. 4.2).
Таблица 4.2
Расчетная таблица выборки
Для совокупности более 100000 выборка составляет 400 единиц. Если же иметь в виду генеральные совокупности численностью от 5 тыс. и больше, то, по расчетам того же автора, можно указать величины фактической ошибки выборки в зависимости от ее объема, что для нас весьма важно, памятуя, что величина допустимой ошибки зависит от цели исследования и необязательно должна приближаться к 5-процентному уровню.
Таблица 4.3
Расчетная таблица
|
Объем выборки, если генеральная совокупность 5000 | ||||||||
|
Фактическая ошибка при данном объёме выборки, % |
Наряду со случайными возможны ошибки систематического характера. Они зависят от организации выборочного обследования. Это разнообразные смещения выборки в сторону одного из полюсов выборочного параметра.
3. Объем выборки на основе статистического анализа . Этот подход основан на определении минимального объема выборки исходя из определенных требований к надежности и достоверности получаемых результатов. Он также используется при анализе полученных результатов для отдельных подгрупп, формируемых в составе выборки по полу, возрасту, уровню образования и т.п. Требования к надежности и точности результатов для отдельных подгрупп диктуют определенные требования к объему выборки в целом.
Наиболее теоретически обоснованный и корректный подход к определению объема выборки основан на расчете достоверных интервалов. Понятие вариации характеризует величину несхожести (схожести) ответов респондентов на определенный вопрос. В более строгом плане вариацией значений какого-либо признака в совокупности называется различие его значений у разных единиц данной совокупности в один и тот же период или момент времени. Результаты ответов на вопросы опроса обычно представляются в форме кривой распределения (рис. 4.1). При высокой схожести ответов говорят о малой вариации (узкая кривая распределения) и при низкой схожести ответов – о высокой вариации (широкая кривая распределения).
В качестве меры вариации обычно принимается среднее квадратическое отклонение, которое характеризует среднее расстояние от средней оценки ответов каждого респондента на определенный вопрос.
Малая вариация
Высокая вариация
Рис. 4.1. Вариация и кривые распределения
Поскольку все маркетинговые решения принимаются в условиях неопределенности, то это обстоятельство целесообразно учесть при определении объема выборки. Так как определение исследуемых величин для совокупности в узком осуществляется на основе выборочной статистики, то следует установить диапазон (доверительный интервал), в который, как ожидается, попадут оценки для совокупности в целом, и ошибку их определения.
Доверительный интервал – это диапазон, крайним точкам которого соответствует определенный процент определенных ответов на какой-то вопрос. Доверительный интервал тесно связан со средним квадратическим отклонением изучаемого признака в генеральной совокупности: чем оно больше, тем шире должен быть доверительный интервал, чтобы включить в свой состав определенный процент ответов.
Доверительный интервал, равный или 95 %, или 99 %, является стандартным при проведении маркетинговых исследований. Ни одна фирма не проводит маркетинговых исследований, формируя несколько выборок. И математическая статистика дает возможность получить некую информацию о выборочном распределении, владея только данными о вариации единственной выборки.
Индикатором степени отличия оценки, истинной для совокупности в целом, от оценки, которая ожидается для типичной выборки, является средняя квадратическая ошибка. Причем, чем больше объем выборки, тем меньше ошибка. Высокое значение вариации обусловливает высокое значение ошибки и наоборот.
Когда на заданный вопрос существует только два варианта ответа, выраженные в процентах (используется процентная мера), объем выборки определяется по следующей формуле:

где n – объем выборки; z – нормированное отклонение, определяемое исходя из выбранного уровня доверительности; p – найденная вариация для выборки; g – (100-р); е – допустимая ошибка.
При определении показателя вариации для определенной совокупности прежде всего целесообразно провести предварительный качественный анализ исследуемой совокупности, в первую очередь установить схожесть единиц совокупности в демографическом, социальном и других отношениях, представляющих интерес для исследователя. Возможно проведение пилотного исследования, использование результатов подобных исследований, проведенных в прошлом. При использовании процентной меры изменчивости принимается в расчет то обстоятельство, что максимальная изменчивость достигается для р = 50 %, что является наихудшим случаем. К тому же этот показатель радикальным образом не влияет на объем выборки. Учитывается также мнение заказчика исследования об объеме выборки.
Возможно определение объема выборки на основе использования средних значений, а не процентных величин.

где s – среднее квадратическое отклонение.
На практике, если выборка формируется заново и схожие опросы не проводились, то s не известно. В этом случае целесообразно задавать погрешность е в долях от среднеквадратического отклонения. Расчетная формула преобразуется и приобретает следующий вид:
 где
где
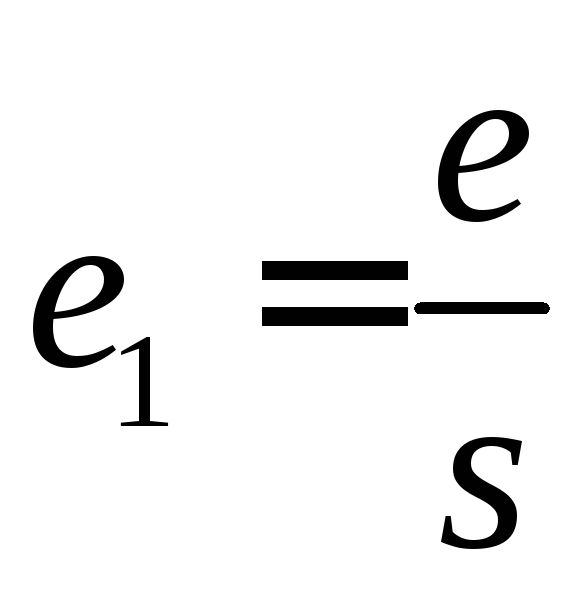 .
.
Выше шел разговор о совокупностях очень больших размеров. Однако в ряде случаев совокупности не являются большими. Обычно, если выборка составляет менее пяти процентов от совокупности, то совокупность считается большой и расчеты проводятся по вышеприведенным правилам. Если объем выборки превышает 5 % от совокупности, то последняя считается малой и в вышеприведенные формулы вводится поправочный коэффициент.
Объем выборки в данном случае определяется следующим образом:
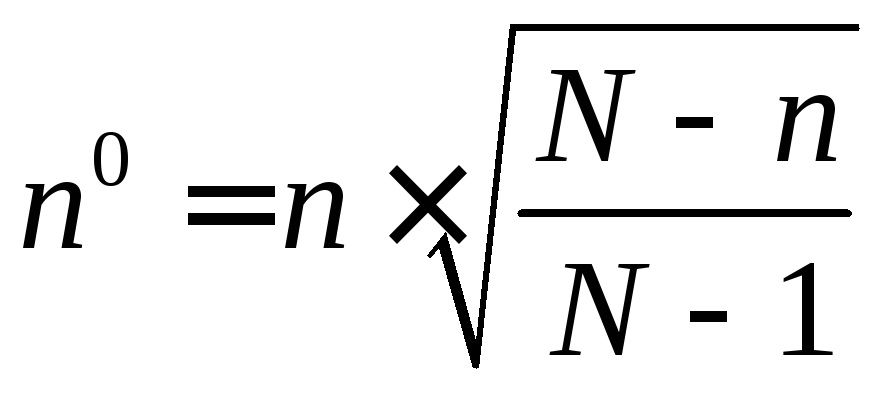 ,
,
где n - объем выборки для малой совокупности; n 0 – объем выборки, рассчитанный по приведенным выше формулам; N – объем генеральной совокупности.
Очевидно, что использование выборки меньших размеров приведет к экономии времени и средств.
Приведенные формулы расчета объема выборки основаны на предположении, что все правила формирования выборки были соблюдены и единственной ошибкой выборки является ошибка, обусловленная ее объемом. Однако, следует помнить, что объем выборки определяет точность полученных результатов, но не их представительность.
Последняя определяется методом формирования выборки. Все формулы для расчета объема выборки предполагают, что репрезентативность гарантируется использованием корректных вероятностных процедур формирования выборки.
Объем, выборки определяется аналитическими, задачами исследования, а ее репрезентативность - целевой установкой программы. Именно программа задает образ необходимой генеральной совокупности для проведения выборки. Будет ли это все население или особые его структурные образования, все элементы изучаемого объекта или только выделяемые по заданным программой критериям, генеральную совокупность составляют все единицы, определенного в программе объекта.
При детерминированном подхода к структуре выборки в общем случае не представляется возможным расчетным путем точно определить ее объем в соответствии с заданным критерием достоверности полученной информации. В этом случае объем выборки может быть определен эмпирически. Ориентиром здесь может служить опыт проведения маркетинговых исследований за рубежом. Так, при обследовании покупателей высокая точность выборки обеспечивается, даже если ее объем не превышает 1% всей совокупности при проведении опросов покупателей средних и крупных розничных фирм, количество опрашиваемых (объем выборки), как правило, колеблется от 500 до 1000 человек.
Значение процедуры выбора метода сбора первичной информации, и орудия исследования состоит в том, что результаты этого выбора определяют как достоверность и точность подлежащей сбору информации, так и продолжительность, и дороговизну ее сбора.