Определение множественного коэффициента корреляции в MS Excel. Дана матрица парных коэффициентов корреляции
Множественная регрессия не является результатом преобразования уравнения:
-
 ;
;
-
 .
.
Линеаризация подразумевает процедуру …
- приведения уравнения множественной регрессии к парной;
+ приведения нелинейного уравнения к линейному виду;
- приведения линейного уравнения к нелинейному виду;
- приведения нелинейного уравнения относительно параметров к уравнению, линейному относительно результата.
Остатки не изменяются;
Уменьшается количество наблюдений
В стандартизованном уравнении множественной регрессии переменными являются:
Исходные переменные;
Стандартизованные параметры;
Средние значения исходных переменных;
Стандартизованные переменные.
Одним из методов присвоения числовых значений фиктивным переменным является. . .
+– ранжирование;
Выравнивание числовых значений по возрастанию;
Выравнивание числовых значений по убыванию;
Нахождение среднего значения.
В матрице парных коэффициентов корреляции отображены значения парных коэффициентов линейной корреляции между. . . .
Переменными;
Параметрами;
Параметрами и переменными;
Переменными и случайными факторами.
Метод оценки параметров моделей с гетероскедастичными остатками называется ____________ методом наименьших квадратов:
Обычным;
Косвенным;
Обобщенным;
Минимальным.
Дано уравнение регрессии . Определите спецификацию модели.
Полиномиальное уравнение парной регрессии;
Линейное уравнение простой регрессии;
Полиномиальное уравнение множественной регрессии;
Линейное уравнение множественной регрессии.
В стандартизованном уравнении свободный член ….
Равен 1;
Равен коэффициенту множественной детерминации;
Равен коэффициенту множественной корреляции;
Отсутствует.
В качестве фиктивных переменных в модель множественной регрессии включаются факторы,
Имеющие вероятностные значения;
Имеющие количественные значения;
Не имеющие качественных значений;
Не имеющие количественных значений.
Факторы эконометрической модели являются коллинеарными, если коэффициент …
Корреляции между ними по модулю больше 0,7;
Детерминации между ними по модулю больше 0,7;
Детерминации между ними по модулю меньше 0,7;
Обобщенный метод наименьших квадратов отличается от обычного МНК тем, что при применении ОМНК …
Преобразуются исходные уровни переменных;
Остатки не изменяются;
Остатки приравниваются к нулю;
Уменьшается количество наблюдений.
Объем выборки определяется …
Числовыми значением переменных, отбираемых в выборку;
Объемом генеральной совокупности;
Числом параметров при независимых переменных;
Числом результативных переменных.
11. Множественная регрессия не является результатом преобразования уравнения:
+-
 ;
;
-
 ;
;
-
 .
.
Исходные значения фиктивных переменных предполагают значения …
Качественные;
Количественно измеримые;
Одинаковые;
Значения.
Обобщенный метод наименьших квадратов подразумевает …
Преобразование переменных;
Переход от множественной регрессии к парной;
Линеаризацию уравнения регрессии;
Двухэтапное применение метода наименьших квадратов.
Линейное
уравнение множественной регрессии
имеет вид
.
Определите какой из факторов или
или
 :
:
+-
 ,
так как 3,7>2,5;
,
так как 3,7>2,5;
Оказывают одинаковое влияние;
-
 ,
так как 2,5>-3,7;
,
так как 2,5>-3,7;
По этому уравнению нельзя ответить на поставленный вопрос, так как коэффициенты регрессии несравнимы между собой.
Включение фактора в модель целесообразно, если коэффициент регрессии при этом факторе является …
Нулевым;
Незначимым;
Существенным;
Несущественным.
Что преобразуется при применении обобщенного метода наименьших квадратов?
Стандартизованные коэффициенты регрессии;
Дисперсия результативного признака;
Исходные уровни переменных;
Дисперсия факторного признака.
Проводится исследование зависимости выработки работника предприятия от ряда факторов. Примером фиктивной переменной в данной модели будет являться ______ работника.
Возраст;
Уровень образования;
Заработная плата.
Переход от точечного оценивания к интервальному возможен, если оценки являются:
Эффективными и несостоятельными;
Неэффективными и состоятельными;
Эффективными и несмещенными;
Состоятельными и смещенными.
Матрица парных коэффициентов корреляции строится для выявления коллинеарных и мультиколлинеарных …
Параметров;
Случайных факторов;
Существенных факторов;
Результатов.
На основании преобразования переменных при помощи обобщенного метода наименьших квадратов получаем новое уравнение регрессии, которое представляет собой:
Взвешенную регрессию, в которой
переменные взяты с весами
 ;
;
 ;
;
Нелинейную регрессию, в которой
переменные взяты с весами
 ;
;
Взвешенную регрессию, в которой
переменные взяты с весами
 .
.
Если расчетное значение критерия Фишера меньше табличного значения, то гипотеза о статистической незначимости уравнения …
Отвергается;
Незначима;
Принимается;
Несущественна.
Если факторы входят в модель как произведение, то модель называется:
Суммарной;
Производной;
Аддитивной;
Мультипликативной.
Уравнение регрессии, которое связывает результирующий признак с одним из факторов при зафиксированных на среднем уровне значении других переменных, называется:
Множественным;
Существенным;
Частным;
Несущественным.
Относительно количества факторов, включенных в уравнение регрессии, различают …
Линейную и нелинейную регрессии;
Непосредственную и косвенную регрессии;
Простую и множественную регрессию;
Множественную и многофакторную регрессию.
Требованием к уравнениям регрессии, параметры которых можно найти при помощи МНК является:
Равенство нулю значений факторного признака4
Нелинейность параметров;
Равенство нулю средних значений результативной переменной;
Линейность параметров.
Метод наименьших квадратов не применим для …
Линейных уравнений парной регрессии;
Полиномиальных уравнений множественной регрессии;
Уравнений, нелинейных по оцениваемым параметрам;
Линейных уравнений множественной регрессии.
При включении фиктивных переменных в модель им присваиваются …
Нулевые значения;
Числовые метки;
Одинаковые значения;
Качественные метки.
Если между экономическими показателями существует нелинейная связь, то …
Нецелесообразно использовать спецификацию нелинейного уравнения регрессии;
Целесообразно использовать спецификацию нелинейного уравнения регрессии;
Целесообразно использовать спецификацию линейного уравнение парной регрессии;
Необходимо включить в модель другие факторы и использовать линейное уравнение множественной регрессии.
Результатом линеаризации полиномиальных уравнений является …
Нелинейные уравнения парной регрессии;
Линейные уравнения парной регрессии;
Нелинейные уравнения множественной регрессии;
Линейные уравнения множественной регрессии.
В
стандартизованном уравнении множественной
регрессии
 0,3;
0,3; -2,1.
Определите, какой из факторов
-2,1.
Определите, какой из факторов или
или оказывает более сильное влияние на
оказывает более сильное влияние на :
:
+-
 ,
так как 2,1>0,3;
,
так как 2,1>0,3;
По этому уравнению нельзя ответить на поставленный вопрос, так как неизвестны значения «чистых» коэффициентов регрессии;
-
 ,
так как 0,3>-2,1;
,
так как 0,3>-2,1;
По этому уравнению нельзя ответить на поставленный вопрос, так как стандартизированные коэффициенты несравнимы между собой.
Факторные переменные уравнения множественной регрессии, преобразованные из качественных в количественные называются …
Аномальными;
Множественными;
Парными;
Фиктивными.
Оценки параметров линейного уравнения множественной регрессии можно найти при помощи метода:
Средних квадратов;
Наибольших квадратов;
Нормальных квадратов;
Наименьших квадратов.
Основным требованием к факторам, включаемым в модель множественной регрессии, является:
Отсутствие взаимосвязи между результатом и фактором;
Отсутствие взаимосвязи между факторами;
Отсутствие линейной взаимосвязи между факторами;
Наличие тесной взаимосвязи между факторами.
Фиктивные переменные включаются в уравнение множественной регрессии для учета действия на результат признаков …
Качественного характера;
Количественного характера;
Несущественного характера;
Случайного характера.
Из пары коллинеарных факторов в эконометрическую модель включается тот фактор,
Который при достаточно тесной связи с результатом имеет наибольшую связь с другими факторами;
Который при отсутствии связи с результатом имеет максимальную связь с другими факторами;
Который при отсутствии связи с результатом имеет наименьшую связь с другими факторами;
Который при достаточно тесной связи с результатом имеет меньшую связь с другими факторами.
Гетероскедастичность подразумевает …
Постоянство дисперсии остатков независимо от значения фактора;
Зависимость математического ожидания остатков от значения фактора;
Зависимость дисперсии остатков от значения фактора;
Независимость математического ожидания остатков от значения фактора.
Величина остаточной дисперсии при включении существенного фактора в модель:
Не изменится;
Будет увеличиваться;
Будет равно нулю;
Будет уменьшаться.
Если спецификация модели отображает нелинейную форму зависимости между экономическими показателями, то нелинейно уравнение …
Регрессии;
Детерминации;
Корреляции;
Аппроксимации.
Исследуется зависимость, которая характеризуется линейным уравнением множественной регрессии. Для уравнения рассчитано значение тесноты связи результативной переменной с набором факторов. В качестве этого показателя был использован множественный коэффициент …
Корреляции;
Эластичности;
Регрессии;
Детерминации.
Строится модель зависимости спроса от ряда факторов. Фиктивной переменной в данном уравнении множественной регрессии не является _________потребителя.
Семейное положение;
Уровень образования;
Для существенного параметра расчетное значение критерия Стьюдента …
Больше табличного значения критерия;
Равно нулю;
Не больше табличного значения критерия Стьюдента;
Меньше табличного значения критерия.
Систему МНК, построенную для оценки параметров линейного уравнения множественной регрессии можно решить …
Методом скользящего среднего;
Методом определителей;
Методом первых разностей;
Симплекс-методом.
Показатель, характеризующий на сколько сигм изменится в среднем результат при изменении соответствующего фактора на одну сигму, при неизменном уровне других факторов, называется ____________коэффициентом регрессии
Стандартизованным;
Нормализованным;
Выровненным;
Центрированным.
Мультиколлинеарность факторов эконометрической модели подразумевает …
Наличие нелинейной зависимости между двумя факторами;
Наличие линейной зависимости между более чем двумя факторами;
Отсутствие зависимости между факторами;
Наличие линейной зависимости между двумя факторами.
Обобщенный метод наименьших квадратов не используется для моделей с _______ остатками.
Автокоррелированными и гетероскедастичными;
Гомоскедастичными;
Гетероскедастичными;
Автокоррелированными.
Методом присвоения числовых значений фиктивным переменным не является:
Ранжирование;
Присвоение цифровых меток;
Нахождения среднего значения;
Присвоение количественных значений.
Нормально распределенных остатков;
Гомоскедастичных остатков;
Автокорреляции остатков;
Автокорреляции результативного признака.
Отбор факторов в модель множественной регрессии при помощи метода включения основан на сравнении значений …
Общей дисперсии до и после включения фактора в модель;
Остаточной дисперсии до и после включения случайных факторов в модель;
Дисперсии до и после включения результата в модель;
Остаточной дисперсии до и после включения фактора модель.
Обобщенный метод наименьших квадратов используется для корректировки …
Параметров нелинейного уравнения регрессии;
Точности определения коэффициента множественной корреляции;
Автокорреляции между независимыми переменными;
Гетероскедастичности остатков в уравнении регрессии.
После применения обобщенного метода наименьших квадратов удается избежать_________ остатков
Гетероскедастичности;
Нормального распределения;
Равенства нулю суммы;
Случайного характера.
Фиктивные переменные включаются в уравнения ____________регрессии
Случайной;
Парной;
Косвенной;
Множественной.
Взаимодействие факторов эконометрической модели означает, что …
Влияние факторов на результирующий признак зависит от значений другого неколлинеарного им фактора;
Влияние факторов на результирующий признак усиливается, начиная с определенного уровня значений факторов;
Факторы дублируют влияние друг друга на результат;
Влияние одного из факторов на результирующий признак не зависит от значений другого фактора.
Тема Множественная регрессия (Задачи)
Уравнение регрессии, построенное по 15 наблюдениям, имеет вид:

Пропущенные значения, а также доверительный интервал для
 с вероятностью
0,99 равны:
с вероятностью
0,99 равны:
Уравнение регрессии, построенное по 20 наблюдениям, имеет вид:

 с вероятностью 0,9 равны:
с вероятностью 0,9 равны:
Уравнение регрессии, построенное по 16 наблюдениям, имеет вид:

Пропущенные
значения, а также доверительный интервал
для
 с вероятностью 0,99 равны:
с вероятностью 0,99 равны:

Уравнение регрессии в стандартизированном виде имеет вид:

Частные коэффициенты эластичности равны:

Стандартизованное уравнение регрессии имеет вид:
Частные коэффициенты эластичности равны:

Стандартизованное уравнение регрессии имеет вид:
Частные коэффициенты эластичности равны:

Стандартизованное уравнение регрессии имеет вид:
Частные коэффициенты эластичности равны:

Стандартизованное уравнение регрессии имеет вид:
Частные коэффициенты эластичности равны:

По 18 наблюдениям получены следующие данные:
 ;
;  ;
; ;
; ;
;
 равны:
равны:
По 17 наблюдениям получены следующие данные:
 ;
;  ;
; ;
; ;
;
Значения
скорректированного коэффициента
детерминации, частных коэффициентов
эластичности и параметра
 равны:
равны:
По 22 наблюдениям получены следующие данные:
 ;
;  ;
; ;
; ;
;
Значения
скорректированного коэффициента
детерминации, частных коэффициентов
эластичности и параметра
 равны:
равны:
По 25 наблюдениям получены следующие данные:
 ;
;  ;
; ;
; ;
;
Значения
скорректированного коэффициента
детерминации, частных коэффициентов
эластичности и параметра
 равны:
равны:
По 24 наблюдениям получены следующие данные:
 ;
;  ;
; ;
; ;
;
Значения
скорректированного коэффициента
детерминации, частных коэффициентов
эластичности и параметра
 равны:
равны:
По 28 наблюдениям получены следующие данные:
 ;
;  ;
; ;
; ;
;
Значения
скорректированного коэффициента
детерминации, частных коэффициентов
эластичности и параметра
 равны:
равны:
По 26 наблюдениям получены следующие данные:
 ;
;  ;
; ;
; ;
;
Значения
скорректированного коэффициента
детерминации, частных коэффициентов
эластичности и параметра
 равны:
равны:
В
уравнении регрессии:

Восстановить
пропущенные характеристики; построить
доверительный интервал для
 с вероятностью 0,95, еслиn=12
с вероятностью 0,95, еслиn=12
Для определения степени зависимости между несколькими показателями применяется множественные коэффициенты корреляции. Их затем сводят в отдельную таблицу, которая имеет название корреляционной матрицы. Наименованиями строк и столбцов такой матрицы являются названия параметров, зависимость которых друг от друга устанавливается. На пересечении строк и столбцов располагаются соответствующие коэффициенты корреляции. Давайте выясним, как можно провести подобный расчет с помощью инструментов Excel.
Принято следующим образом определять уровень взаимосвязи между различными показателями, в зависимости от коэффициента корреляции:
- 0 – 0,3 – связь отсутствует;
- 0,3 – 0,5 – связь слабая;
- 0,5 – 0,7 – средняя связь;
- 0,7 – 0,9 – высокая;
- 0,9 – 1 – очень сильная.
Если корреляционный коэффициент отрицательный, то это значит, что связь параметров обратная.
Для того, чтобы составить корреляционную матрицу в Экселе, используется один инструмент, входящий в пакет «Анализ данных» . Он так и называется – «Корреляция» . Давайте узнаем, как с помощью него можно вычислить показатели множественной корреляции.
Этап 1: активация пакета анализа
Сразу нужно сказать, что по умолчанию пакет «Анализ данных» отключен. Поэтому, прежде чем приступить к процедуре непосредственного вычисления коэффициентов корреляции, нужно его активировать. К сожалению, далеко не каждый пользователь знает, как это делать. Поэтому мы остановимся на данном вопросе.


После указанного действия пакет инструментов «Анализ данных» будет активирован.
Этап 2: расчет коэффициента
Теперь можно переходить непосредственно к расчету множественного коэффициента корреляции. Давайте на примере представленной ниже таблицы показателей производительности труда, фондовооруженности и энерговооруженности на различных предприятиях рассчитаем множественный коэффициент корреляции указанных факторов.


Этап 3: анализ полученного результата
Теперь давайте разберемся, как понимать тот результат, который мы получили в процессе обработки данных инструментом «Корреляция» в программе Excel.
Как видим из таблицы, коэффициент корреляции фондовооруженности (Столбец 2 ) и энерговооруженности (Столбец 1 ) составляет 0,92, что соответствует очень сильной взаимосвязи. Между производительностью труда (Столбец 3 ) и энерговооруженностью (Столбец 1 ) данный показатель равен 0,72, что является высокой степенью зависимости. Коэффициент корреляции между производительностью труда (Столбец 3 ) и фондовооруженностью (Столбец 2 ) равен 0,88, что тоже соответствует высокой степени зависимости. Таким образом, можно сказать, что зависимость между всеми изучаемыми факторами прослеживается довольно сильная.
Как видим, пакет «Анализ данных» в Экселе представляет собой очень удобный и довольно легкий в обращении инструмент для определения множественного коэффициента корреляции. С его же помощью можно производить расчет и обычной корреляции между двумя факторами.
Анализ матрицы парных коэффициентов корреляции показывает, что результативный показатель наиболее тесно связан с показателем x (4) - количество удобрений, расходуемых на 1 га ().
В то же время
связь между признаками-аргументами
достаточно тесная. Так, существует
практически функциональная связь между
числом колесных тракторов (x
(1))
и числом орудий поверхностной обработки
почвы .
.
О наличии
мультиколлинеарности свидетельствуют
также коэффициенты корреляции
 и
и .
Учитывая тесную взаимосвязь показателейx
(1) , x
(2) и x
(3) ,
в регрессионную модель урожайности
может войти лишь один из них.
.
Учитывая тесную взаимосвязь показателейx
(1) , x
(2) и x
(3) ,
в регрессионную модель урожайности
может войти лишь один из них.
Чтобы продемонстрировать отрицательное влияние мультиколлинеарности, рассмотрим регрессионную модель урожайности, включив в нее все исходные показатели:

 F набл
= 121.
F набл
= 121.
В скобках
указаны значения исправленных оценок
среднеквадратических отклонений оценок
коэффициентов уравнения
 .
.
Под уравнением
регрессии представлены следующие его
параметры адекватности: множественный
коэффициент детерминации
 ;
исправленная оценка остаточной дисперсии
;
исправленная оценка остаточной дисперсии ,
средняя относительная ошибка аппроксимациии расчетное значение-критерия
F набл = 121.
,
средняя относительная ошибка аппроксимациии расчетное значение-критерия
F набл = 121.
Уравнение регрессии значимо, т.к. F набл = 121 > F kp = 2,85 найденного по таблицеF -распределения при=0,05; 1 =6 и 2 =14.
Из этого следует, что 0, т.е. и хотя бы один из коэффициентов уравнения j (j = 0, 1, 2, ..., 5) не равен нулю.
Для проверки
гипотезы о значимости отдельных
коэффициентов регрессии H0: j =0,
гдеj
=1,2,3,4,5, сравнивают критическое
значениеt
kp = 2,14, найденное по
таблицеt
-распределения при уровне
значимости=2Q
=0,05
и числе степеней свободы=14,
с расчетным значением .
Из уравнения следует, что статистически
значимым является коэффициент регрессии
только при x
(4) , так какt
4 =2,90
>t
kp =2,14.
.
Из уравнения следует, что статистически
значимым является коэффициент регрессии
только при x
(4) , так какt
4 =2,90
>t
kp =2,14.
Не поддаются экономической интерпретации отрицательные знаки коэффициентов регрессии при x (1) и x (5) . Из отрицательных значений коэффициентов следует, что повышение насыщенности сельского хозяйства колесными тракторами (x (1)) и средствами оздоровления растений (x (5)) отрицательно сказывается на урожайности. Таким образом, полученное уравнение регрессии неприемлемо.
Для получения уравнения регрессии со значимыми коэффициентами используем пошаговый алгоритм регрессионного анализа. Первоначально используем пошаговый алгоритм с исключением переменных.
Исключим из модели переменную x (1) , которой соответствует минимальное по абсолютной величине значениеt 1 =0,01. Для оставшихся переменных вновь построим уравнение регрессии:
Полученное уравнение значимо, т.к. F набл = 155 > F kp = 2,90, найденного при уровне значимости=0,05 и числах степеней свободы 1 =5 и 2 =15 по таблицеF -распределения, т.е. вектор0. Однако в уравнении значим только коэффициент регрессии приx (4) . Расчетные значенияt j для остальных коэффициентов меньшеt кр = 2,131, найденного по таблицеt -распределения при=2Q =0,05 и=15.
Исключив из модели переменную x (3) , которой соответствует минимальное значениеt 3 =0,35 и получим уравнение регрессии:
 (2.9)
(2.9)
В полученном уравнении статистически не значим и экономически не интерпретируем коэффициент при x (5) . Исключивx (5) получим уравнение регрессии:
 (2.10)
(2.10)
Мы получили значимое уравнение регрессии со значимыми и интерпретируемыми коэффициентами.
Однако полученное уравнение является не единственно “хорошей” и не “самой лучшей” моделью урожайности в нашем примере.
Покажем, что в условии мультиколлинеарности пошаговый алгоритм с включением переменных является более эффективным. На первом шаге в модель урожайностиy входит переменная x (4) , имеющая самый высокий коэффициент корреляции сy , объясняемой переменнойr (y , x (4))=0,58. На втором шаге, включая уравнение наряду сx (4) переменныеx (1) илиx (3) , мы получим модели, которые по экономическим соображениям и статистическим характеристикам превосходят (2.10):
 (2.11)
(2.11)
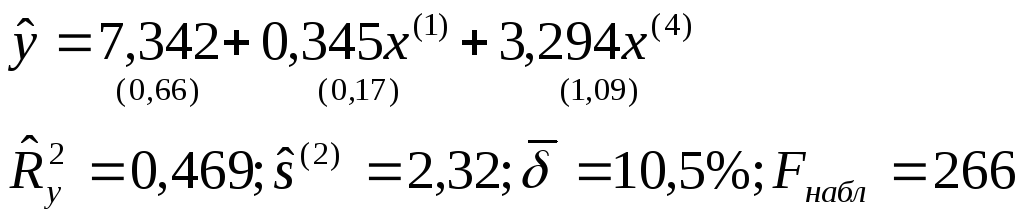 (2.12)
(2.12)
Включение в уравнение любой из трех оставшихся переменных ухудшает его свойства. Смотри, например, уравнение (2.9).
Таким образом, мы имеем три “хороших” модели урожайности, из которых нужно выбрать по экономическим и статистическим соображениям одну.
По статистическим
критериям наиболее адекватна модель
(2.11). Ей соответствуют минимальные
значения остаточной дисперсии
 =2,26
и средней относительной ошибки
аппроксимациии наибольшие значения
=2,26
и средней относительной ошибки
аппроксимациии наибольшие значения и F набл = 273.
и F набл = 273.
Несколько худшие показатели адекватности имеет модель (2.12), а затем - модель (2.10).
Будем теперь выбирать наилучшую из моделей (2.11) и (2.12). Эти модели отличаются друг от друга переменными x (1) иx (3) . Однако в моделях урожайностей переменнаяx (1) (число колесных тракторов на 100 га) более предпочтительна, чем переменнаяx (3) (число орудий поверхностной обработки почвы на 100 га), которая является в некоторой степени вторичной (или производной от x (1)).
В этой связи из экономических соображений предпочтение следует отдать модели (2.12). Таким образом, после реализации алгоритма пошагового регрессионного анализа с включением переменных и учета того, что в уравнение должна войти только одна из трех связанных переменных (x (1) ,x (2) илиx (3)) выбираем окончательное уравнение регрессии:

Уравнение
значимо при =0,05,
т.к. F набл = 266 > F kp = 3,20,
найденного по таблицеF
-распределения
при=Q
=0,05; 1 =3
и 2 =17. Значимы
и все коэффициенты регрессии и
и в уравненииt
j >t
kp (=2Q
=0,05;=17)=2,11. Коэффициент
регрессии 1 следует признать значимым ( 1 0)
из экономических соображений, при этомt
1 =2,09 лишь незначительно меньшеt
kp = 2,11.
в уравненииt
j >t
kp (=2Q
=0,05;=17)=2,11. Коэффициент
регрессии 1 следует признать значимым ( 1 0)
из экономических соображений, при этомt
1 =2,09 лишь незначительно меньшеt
kp = 2,11.
Из уравнения регрессии следует, что увеличение на единицу числа тракторов на 100 га пашни (при фиксированном значении x (4)) приводит к росту урожайности зерновых в среднем на 0,345 ц/га.
Приближенный расчет коэффициентов эластичности э 1 0,068 и э 2 0,161 показывает, что при увеличении показателейx (1) иx (4) на 1% урожайность зерновых повышается в среднем соответственно на 0,068% и 0,161%.
Множественный
коэффициент детерминации
 свидетельствует о том, что только 46,9%
вариации урожайности объясняется
вошедшими в модель показателями (x
(1) иx
(4)), то есть насыщенностью
растениеводства тракторами и удобрениями.
Остальная часть вариации обусловлена
действием неучтенных факторов (x
(2) ,x
(3) ,x
(5) , погодные
условия и др.). Средняя относительная
ошибка аппроксимациихарактеризует адекватность модели, так
же как и величина остаточной дисперсии
свидетельствует о том, что только 46,9%
вариации урожайности объясняется
вошедшими в модель показателями (x
(1) иx
(4)), то есть насыщенностью
растениеводства тракторами и удобрениями.
Остальная часть вариации обусловлена
действием неучтенных факторов (x
(2) ,x
(3) ,x
(5) , погодные
условия и др.). Средняя относительная
ошибка аппроксимациихарактеризует адекватность модели, так
же как и величина остаточной дисперсии .
При интерпретации уравнения регрессии
интерес представляют значения
относительных ошибок аппроксимации
.
При интерпретации уравнения регрессии
интерес представляют значения
относительных ошибок аппроксимации .
Напомним, что
.
Напомним, что -
модельное значение результативного
показателя, характеризует среднее для
совокупности рассматриваемых районов
значение урожайности при условии, что
значения объясняющих переменныхx
(1) иx
(4) зафиксированы на одном
и том же уровне, а именноx
(1) =x
i
(1) иx
(4)
= x
i
(4) . Тогда по значениям i
можно
сопоставлять районы по урожайности.
Районы, которым соответствуют значения i
>0, имеют
урожайность выше среднего, а i
<0
- ниже среднего.
-
модельное значение результативного
показателя, характеризует среднее для
совокупности рассматриваемых районов
значение урожайности при условии, что
значения объясняющих переменныхx
(1) иx
(4) зафиксированы на одном
и том же уровне, а именноx
(1) =x
i
(1) иx
(4)
= x
i
(4) . Тогда по значениям i
можно
сопоставлять районы по урожайности.
Районы, которым соответствуют значения i
>0, имеют
урожайность выше среднего, а i
<0
- ниже среднего.
В нашем примере, по урожайности наиболее эффективно растениеводство ведется в районе, которому соответствует 7 =28%, где урожайность на 28% выше средней по региону, и наименее эффективно - в районе с 20 =27,3%.
| Y | X 1 | X 2 | X 3 | X 4 | X 5 | X 6 | |
| Y | |||||||
| X 1 | 0,519 | ||||||
| X 2 | -0,273 | 0,030 | |||||
| X 3 | 0,610 | 0,813 | -0,116 | ||||
| X 4 | -0,572 | -0,013 | -0,022 | -0,091 | |||
| X 5 | 0,297 | 0,043 | -0,461 | 0,120 | -0,359 | ||
| X 6 | 0,118 | -0,366 | -0,061 | -0,329 | -0,100 | -0,290 |
Анализ межфакторных (между «иксами»!) коэффициентов корреляции показывает, что значение 0,8 превышает по абсолютной величине только коэффициент корреляции между парой факторов Х 1 –Х 3 (выделен жирным шрифтом). Факторы Х 1 –Х 3 , таким образом, признаются коллинеарными.
2. Как было показано в пункте 1, факторы Х 1 –Х 3 являются коллинеарными, а это означает, что они фактически дублируют друг друга, и их одновременное включение в модель приведет к неправильной интерпретации соответствующих коэффициентов регрессии. Видно, что фактор Х 3 имеет больший по модулю коэффициент корреляции с результатом Y , чем фактор Х 1: r y , x 1 =0,519; r y , x 3 =0,610; (см. табл. 1 ). Это свидетельствует о более сильном влиянии фактора Х 3 на изменение Y . Фактор Х 1 , таким образом, исключается из рассмотрения.
Для построения уравнения регрессии значения используемых переменных (Y , X 2 , X 3 , X 4 , X 5 , X 6) скопируем на чистый рабочий лист (прил. 3) . Уравнение регрессии строим с помощью надстройки «Анализ данных… Регрессия » (меню «Сервис» ® «Анализ данных… » ® «Регрессия »). Панель регрессионного анализа с заполненными полями изображена на рис. 2 .
Результаты регрессионного анализа приведены в прил. 4 и перенесены в табл. 2 . Уравнение регрессии имеет вид (см. «Коэффициенты» втабл. 2 ):
Уравнение регрессии признается статистически значимым, так как вероятность его случайного формирования в том виде, в котором оно получено, составляет 8,80×10 -6 (см. «Значимость F» втабл. 2 ), что существенно ниже принятого уровня значимости a=0,05.
Х 3 , Х 4 , Х 6 ниже принятого уровня значимости a=0,05 (см. «P-Значение» втабл. 2 ), что свидетельствует о статистической значимости коэффициентов и существенном влиянии этих факторов на изменение годовой прибыли Y .
Вероятность случайного формирования коэффициентов при факторах Х 2 и Х 5 превышает принятый уровень значимости a=0,05 (см. «P-Значение» втабл. 2 ), и эти коэффициенты не признаются статистически значимыми.

рис. 2. Панель регрессионного анализа модели Y (X 2 , X 3 , X 4 , X 5 , X 6)
Таблица 2
Y (X 2 , X 3 , X 4 , X 5 , X 6)
| Регрессионная статистика | |||||||||
| Множественный R | 0,868 | ||||||||
| R-квадрат | 0,753 | ||||||||
| Нормированный R-квадрат | 0,694 | ||||||||
| Стандартная ошибка | 242,3 | ||||||||
| Наблюдения | |||||||||
| Дисперсионный анализ | |||||||||
| df | SS | MS | F | Значимость F | |||||
| Регрессия | 3749838,2 | 749967,6 | 12,78 | 8,80E-06 | |||||
| Остаток | 1232466,8 | 58688,9 | |||||||
| Итого | 4982305,0 | ||||||||
| Уравнение регрессии | |||||||||
| Коэффициенты | Стандартная ошибка | t-статистика | P-Значение | ||||||
| Y-пересечение | 487,5 | 641,4 | 0,760 | 0,456 | |||||
| X2 | -0,0456 | 0,0373 | -1,224 | 0,235 | |||||
| X3 | 0,1043 | 0,0194 | 5,375 | 0,00002 | |||||
| X4 | -0,0965 | 0,0263 | -3,674 | 0,001 | |||||
| X5 | 2,528 | 6,323 | 0,400 | 0,693 | |||||
| X6 | 248,2 | 113,0 | 2,197 | 0,039 | |||||
3. По результатам проверки статистической значимости коэффициентов уравнения регрессии, проведенной в предыдущем пункте, строим новую регрессионную модель, содержащую только информативные факторы, к которым относятся:
· факторы, коэффициенты при которых статистически значимы;
· факторы, у коэффициентов которых t ‑статистика превышает по модулю единицу (другими словами, абсолютная величина коэффициента больше его стандартной ошибки).
К первой группе относятся факторы Х 3 , Х 4 , Х 6 , ко второй - фактор X 2 . Фактор X 5 исключается из рассмотрения как неинформативный, и окончательно регрессионная модель будет содержать факторы X 2 , X 3 , X 4 , X 6 .
Для построения уравнения регрессии скопируем на чистый рабочий лист значения используемых переменных (прил. 5) и проведем регрессионный анализ (рис. 3 ). Его результаты приведены в прил. 6 и перенесены в табл. 3 . Уравнение регрессии имеет вид:
(см. «Коэффициенты» втабл. 3 ).

рис. 3. Панель регрессионного анализа модели Y (X 2 , X 3 , X 4 , X 6)
Таблица 3
Результаты регрессионного анализа модели Y (X 2 , X 3 , X 4 , X 6)
| Регрессионная статистика | |||||||||
| Множественный R | 0,866 | ||||||||
| R-квадрат | 0,751 | ||||||||
| Нормированный R-квадрат | 0,705 | ||||||||
| Стандартная ошибка | 237,6 | ||||||||
| Наблюдения | |||||||||
| Дисперсионный анализ | |||||||||
| df | SS | MS | F | Значимость F | |||||
| Регрессия | 3740456,2 | 935114,1 | 16,57 | 2,14E-06 | |||||
| Остаток | 1241848,7 | 56447,7 | |||||||
| Итого | 4982305,0 | ||||||||
| Уравнение регрессии | |||||||||
| Коэффициенты | Стандартная ошибка | t-статистика | P-Значение | ||||||
| Y-пересечение | 712,2 | 303,0 | 2,351 | 0,028 | |||||
| X2 | -0,0541 | 0,0300 | -1,806 | 0,085 | |||||
| X3 | 0,1032 | 0,0188 | 5,476 | 0,00002 | |||||
| X4 | -0,1017 | 0,0223 | -4,560 | 0,00015 | |||||
| X6 | 227,5 | 98,5 | 2,310 | 0,031 | |||||
Уравнение регрессии статистически значимо: вероятность его случайного формирования ниже допустимого уровня значимости a=0,05 (см. «Значимость F» втабл. 3 ).
Статистически значимыми признаются и коэффициенты при факторах Х 3 , Х 4 , Х 6: вероятность их случайного формирования ниже допустимого уровня значимости a=0,05 (см. «P-Значение» втабл. 3 ). Это свидетельствует о существенном влиянии годового размера страховых сборов X 3 , годового размера страховых выплат X 4 и формы собственности X 6 на изменение годовой прибыли Y .
Коэффициент при факторе Х 2 (годовой размер страховых резервов) не является статистически значимым. Однако этот фактор все же можно считать информативным, так как t ‑статистика его коэффициента превышает по модулю единицу, хотя к дальнейшим выводам относительно фактора Х 2 следует относиться с некоторой долей осторожности.
4. Оценим качество и точность последнего уравнения регрессии, используя некоторые статистические характеристики, полученные в ходе регрессионного анализа (см. «Регрессионную статистику » в табл. 3 ):
· множественный коэффициент детерминации

показывает, что регрессионная модель объясняет 75,1 % вариации годовой прибыли Y , причем эта вариация обусловлена изменением включенных в модель регрессии факторов X 2 , X 3 , X 4 и X 6 ;
· стандартная ошибка регрессии
 тыс. руб.
тыс. руб.
показывает, что предсказанные уравнением регрессии значения годовой прибыли Y отличаются от фактических значений в среднем на 237,6 тыс. руб.
Средняя относительная ошибка аппроксимации определяется по приближенной формуле:
где ![]() тыс. руб. - среднее значение годовой прибыли (определено с помощью встроенной функции «СРЗНАЧ
»; прил. 1
).
тыс. руб. - среднее значение годовой прибыли (определено с помощью встроенной функции «СРЗНАЧ
»; прил. 1
).
Е
отн показывает, что предсказанные уравнением регрессии значения годовой прибыли Y
отличаются от фактических значений в среднем на 26,7 %. Модель имеет неудовлетворительную точность (при - точность модели высокая, при ![]() - хорошая, при
- хорошая, при ![]() - удовлетворительная, при - неудовлетворительная).
- удовлетворительная, при - неудовлетворительная).
5. Для экономической интерпретации коэффициентов уравнения регрессии сведем в таблицу средние значения и стандартные отклонения переменных в исходных данных (табл. 4 ) . Средние значения были определены с помощью встроенной функции «СРЗНАЧ », стандартные отклонения - с помощью встроенной функции «СТАНДОТКЛОН » (см. прил. 1 ).
По территориям Южного федерального округа РФ приводятся данные за 2011 год
|
Территории федерального округа |
Валовой региональный продукт, млрд. руб., Y |
Инвестиции в основной капитал, млрд. руб., X1 |
|
1. Респ. Адыгея |
||
|
2. Респ. Дагестан |
||
|
3. Респ. Ингушетия |
||
|
4. Кабардино-БалкарскаяРесп. |
||
|
5. Респ. Калмыкия |
||
|
6. Карачаево-ЧеркесскаяРесп. |
||
|
7. Респ. Северная Осетия - Алания |
||
|
8. Краснодарский кра) |
||
|
9. Ставропольский край |
||
|
10. Астраханская обл. |
||
|
11. Волгоградская обл. |
||
|
12. Ростовская обл. |
- 1. Рассчитайте матрицу парных коэффициентов корреляции; оцените статистическую значимость коэффициентов корреляции.
- 2. Постройте поле корреляции результативного признака и наиболее тесно связанного с ним фактора.
- 3. Рассчитайте параметры линейной парной регрессии для каждого фактора Х..
- 4. Оцените качество каждой модели через коэффициент детерминации, среднюю ошибку аппроксимации и F-критерий Фишера. Выберите лучшую модель.
составит 80% от его максимального значения. Представьте графически: фактические и модельные значения, точки прогноза.
- 6. Используя пошаговую множественную регрессию (метод исключения или метод включения), постройте модель формирования цены квартиры за счёт значимых факторов. Дайте экономическую интерпретацию коэффициентов модели регрессии.
- 7. Оцените качество построенной модели. Улучшилось ли качество модели по сравнению с однофакторной моделью? Дайте оценку влияния значимых факторов на результат с помощью коэффициентов эластичности,в - и -? коэффициентов.
При решении данной задачи расчеты и построение графиков и диаграмм будем вести с использованием настройки Excel Анализ данных.
1. Рассчитаем матрицу парных коэффициентов корреляции и оценим статистическую значимость коэффициентов корреляции
В диалоговом окне Корреляция в поле Входной интервал вводим диапазон ячеек, содержащих исходные данные. Так как мы выделили и заголовки столбцов, то устанавливаем флажок Метки в первой строке.
Получили следующие результаты:
Таблица 1.1 Матрица парных коэффициентов корреляции
Анализ матрицы коэффициентов парной корреляции показывает, что зависимая переменная Y, т.е валового регионального продукта имеет более тесную связь с Х1 (инвестиции в основной капитал). Коэффициент корреляции равен 0,936. Это означает, что на 93,6% зависимая переменная Y (валовой региональный продукт) зависит от показателя Х1 (инвестиции в основной капитал).
Статистическая значимость коэффициентов корреляции определим с помощью t-критерия Стьюдента. Табличное значение сравниваем с расчетными значениями.
Вычислим табличное значение с помощью функции СТЬЮДРАСПОБР.
t табл.=0,129 при доверительной вероятности равной 0,9 и степенью свободы (n-2).
Статистическим значимым является фактор Х1.
2. Построим поле корреляции результативного признака (валового регионального продукта) и наиболее тесно связанного с ним фактора (инвестиции в основной капитал)
Для этого воспользуемся инструментом построения точечной диаграммы программы Excel.
В результате получаем поле корреляции цены валового регионального продукта, млрд. руб. и инвестиции в основной капитал, млрд. руб. (рисунок 1.1.).
Рисунок 1.1
3. Рассчитаем параметры линейной парной регрессии для каждого фактора Х
Для расчета параметров линейной парной регрессии воспользуемся инструментом Регрессия, входящим в настойку Анализ данных.
В диалоговом окне Регрессия в поле Входной интервал Y вводим адрес диапазона ячеек, которые представляет зависимую переменную. В поле
Входной интервал Х вводим адрес диапазона, который содержит значения независимых переменных. Выполним вычисления параметры парной регрессии для фактора Х.
Для Х1 получили следующие данные, представленные в таблице 1.2:
Таблица 1.2
Уравнение регрессии зависимости цены валового регионального продукта от инвестиции в основной капитал имеет вид:
4. Оценим качество каждой модели через коэффициент детерминации, среднюю ошибку аппроксимации и F-критерий Фишера. Установим, какая модель является лучшей.
Коэффициент детерминации, среднюю ошибку аппроксимации мы получили в результате расчетов, проведенных в пункте 3. Полученные данные представлены в следующих таблицах:
Данные по Х1:
Таблица 1.3а
Таблица 1.4б
А) Коэффициент детерминации определяет, какая доля вариации признака У учтена в модели и обусловлена влиянием на него фактора Х. Чем больше значение коэффициента детерминации, тем теснее связь между признаками в построенной математической модели.
В программе Excel обозначается R-квадрат.
Исходя из данного критерия наиболее адекватной является модель уравнения регрессии зависимости цены валового регионального продукта от инвестиции в основной капитал (Х1).
Б) Среднюю ошибку аппроксимации рассчитаем по формуле:
где числитель - сумма квадратов отклонения расчетных значений от фактических. В таблицах она находится в столбце SS, строке Остатки.
Среднее значение цены квартиры рассчитаем в Excel с помощью функции СРЗНАЧ. = 24,18182 млрд. руб.
При проведении экономических расчетов модель считается достаточно точной, если средняя ошибка аппроксимации меньше 5%, модель считается приемлемой, если средняя ошибка аппроксимации меньше 15%.
По данному критерию, наиболее адекватной является математическая модель для уравнения регрессии зависимости цены валового регионального продукта от инвестиции в основной капитал (Х1).
В) Для проверки значимости модели регрессии используется F-тест. Для этого выполняется сравнение и критического (табличного)значений F-критерия Фишера.
Расчетные значения приведены в таблицах 1.4б (обозначены буквой F).
Табличное значение F-критерий Фишера рассчитаем в Excel с помощью функции FРАСПОБР. Вероятность возьмем равной 0,05. Получили: = 4,75
Расчетные значения F-критерий Фишера для каждого фактора сравним с табличным значением:
71,02 > = 4,75 модель по данному критерию адекватна.
Проанализировав данные по всем трем критериям, можно сделать вывод, что наиболее лучшей является математическая модель, построена для фактора валового регионального продукта, которая описана линейным уравнением
5. Для выбранной модели зависимости цены валового регионального продукта
осуществим прогнозирование среднего значения показателя при уровне значимости, если прогнозное значения фактора составит 80% от его максимального значения. Представим графически: фактические и модельные значения, точки прогноза.
Рассчитаем прогнозное значение Х, по условию оно составит 80% от максимального значения.
Рассчитаем Х max в Excel с помощью функции МАКС.
0,8 *52,8 = 42,24
Для получения прогнозных оценок зависимой переменной подставим полученное значение независимой переменной в линейное уравнение:
5,07+2,14*42,24 = 304,55 млрд. руб.
Определим доверительный интервал прогноза, который будет иметь следующие границы:
Для вычисления доверительного интервала для прогнозного значения рассчитываем величину отклонения от линии регрессии.
Для модели парной регрессии величина отклонения рассчитывается:


т.е. значение стандартной ошибки из таблицы 1.5а.
(Так как число степеней свободы равно единицы, то знаменатель будет равен n-2). корреляция парная регрессия прогноз
Для расчета коэффициента воспользуемся функцией Excel СТЬЮДРАСПОБР, вероятность возьмем равную 0,1, число степеней свободы 38.
Значение рассчитаем с помощью Excel, получим 12294.

Определим верхнюю и нижнюю границы интервала.
- 304,55+27,472= 332,022
- 304,55-27,472= 277,078
Таким образом, прогнозное значение = 304,55 тыс.долл., будет находиться между нижней границей, равной 277,078 тыс.долл. и верхней границей, равной 332,022 млдр. Руб.
Фактические и модельные значения, точки прогноза представлены графически на рисунке 1.2.

Рисунок 1.2
6. Используя пошаговую множественную регрессию (метод исключения), построим модель формирования цены валового регионального продукта за счёт значимых факторов
Для построения множественной регрессии воспользуемся функцией Регрессия программы Excel, включив в нее все факторы. В результате получаем результативные таблицы, из которых нам необходим t-критерий Стьюдента.
Таблица 1.8а
Таблица 1.8б
Таблица 1.8в.
Получаем модель вида:
Поскольку < (4,75 < 71,024), уравнение регрессии следует признать адекватным.
Выберем наименьшее по модулю значение t-критерия Стьюдента, оно равно 8,427, сравниваем его с табличным значением, которые рассчитываем в Excel, уровень значимости берем равным 0,10, число степеней свободы n-m-1=12-4=8: =1,8595
Поскольку 8,427>1,8595 модель следует признать адекватной.
7. Для оценки значимого фактора полученной математической модели, рассчитаем коэффициенты эластичности, и - коэффициенты
Коэффициент эластичности показывает, насколько процентов изменится результативный признак при изменении факторного признака на 1%:
Э X4 = 2,137 *(10,69/24,182) = 0,94%
То есть с ростом инвестиции в основной капитал 1% стоимость в среднем возрастает на 0,94%.
Коэффициент показывает на какую часть величины среднего квадратического отклонения меняется среднее значение зависимой переменной с изменением независимой переменной на одно среднеквадратическое отклонение.
2,137* (14.736/33,632) = 0,936.
Данные средних квадратических отклонений взяты из таблиц, полученных с помощью инструменты Описательная статистика.
Таблица 1.11 Описательная статистика (Y)
Таблица 1.12 Описательная статистика (Х4)
Коэффициент определяет долю влияния фактора в суммарном влиянии всех факторов:
Для расчета коэффициентов парной корреляции вычисляем матрицу парных коэффициентов корреляции в программе Excel с помощью инструмента Корреляция настройки Анализа данных.
Таблица 1.14
(0,93633*0,93626) / 0,87 = 1,00.
Вывод: Из полученных расчетов можно сделать вывод, что результативный признак Y (валовой региональный продукт) имеет большую зависимость от фактора X1 (инвестиции в основной капитал) (на 100%).
Список литературы
- 1. Магнус Я.Р., Катышев П.К., Пересецкий А.А. Эконометрика. Начальный курс. Учебное пособие. 2-е изд. - М.: Дело, 1998. - с. 69 - 74.
- 2. Практикум по эконометрике: Учебное пособие / И.И. Елисеева, С.В. Курышева, Н.М. Гордеенко и др. 2002. - с. 49 - 105.
- 3. Доугерти К. Введение в эконометрику: Пер. с англ. - М.: ИНФРА-М, 1999. - XIV, с. 262 - 285.
- 4. Айвызян С.А., Михтирян В.С. Прикладная математика и основы эконометрики. -1998., с 115-147 .
- 5. Кремер Н.Ш., Путко Б.А. Эконометрика. -2007. с 175-251.